
Micropower Intelligence for Edge Devices
September 05, 2018
Blog

The world is moving toward a smart and distributed computing model of interacting devices. Intelligence in these devices will be driven by machine learning algorithms.
Abstract:
The world is moving toward a smart and distributed computing model of interacting devices. Intelligence in these devices will be driven by machine learning algorithms. Yet, extending machine learning to the edge is not without its challenges. This paper will discuss the landscape of these challenges and then describe how neuromorphic – brain-inspired – computing will enable a wide range of intelligent applications that address these challenges. Examples of this technology including handwriting recognition and continuous speech recognition are provided.
The world is moving toward a smart and distributed computing model wherein millions of smart devices would directly interact and communicate with their world and with each other to enable a faster more responsive and intelligent future. This world would enable a new breed of edge devices and systems ranging from wearables, smart bulbs, smart locks to smart cars and buildings, with minimal need for any central coordinating or processing entity such as the cloud. At the heart of this smart world is machine learning algorithms that run on processors that directly operate on data collected by these devices to learn to make intelligent inferences and to act upon their world in real time and efficiently under dynamically changing circumstances.
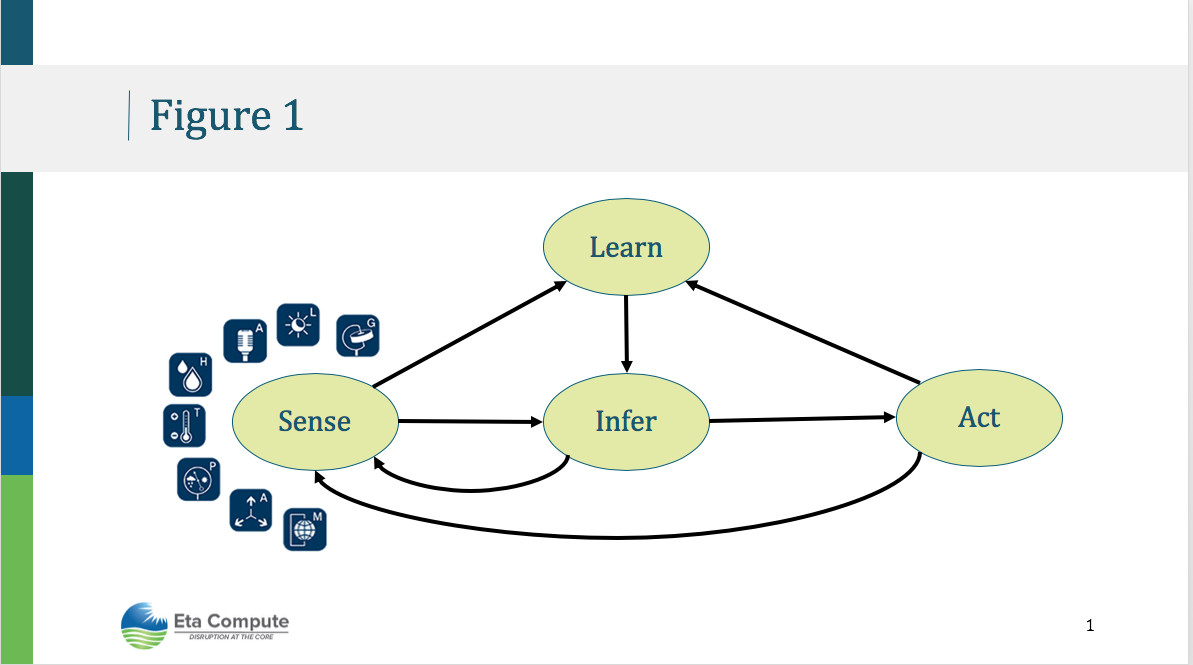
The model for enabling intelligence in edge devices is based on the ability to sense-learn-infer-act during their interaction with their environment and other devices (Figure 1). We believe that solutions that empower these intelligent edge devices to be both agile (i.e., fast response) and efficient (i.e., from a power perspective) will dominate this dynamically changing and distributed world of networked sensors and objects. But, like any new technology, there are several challenges that need to be addressed in delivering low power intelligence at the edge. We review some key challenges and discuss how Eta Compute is working to address them.
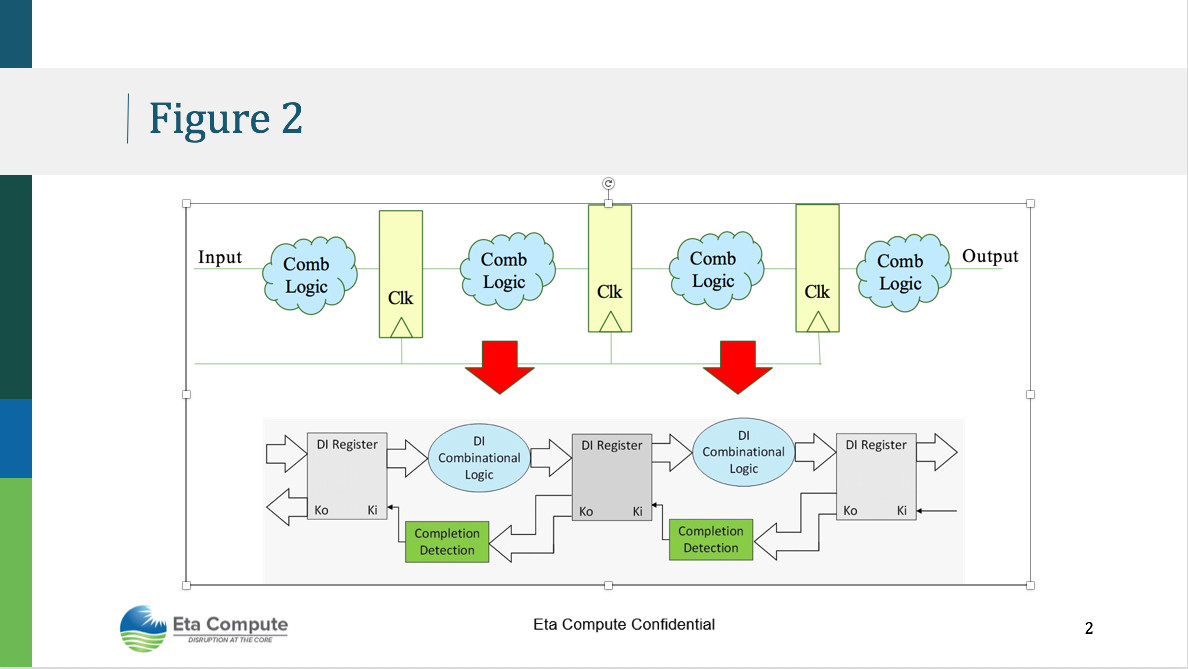
A key challenge is to be able to process data intelligently with very limited power resources on these edge devices. Eta Compute has been developing a foundational technology called DIALTM (i.e., delay insensitive asynchronous logic) to transform the operation of traditional microprocessors and digital signal processors from synchronous to an asynchronous mode (i.e., without any clock). The basic principle unlike traditional logic (see Figure 2) is to run the processor in an event driven fashion waking up to process on demand and sleep when not used via a handshaking protocol. Furthermore, this processor can be automatically controlled to operate at the lowest frequency as demanded by a task and at that frequency to be able to scale the operating voltage to the smallest possible value to run the task. An important innovation of DIAL is that there is no area penalty in the circuit design while also offering a formally verifiable methodology to verify proper circuit function. These important features have enabled Eta Compute to deliver microprocessor technology at the lowest power levels in the industry and a scaling of ~10 μW/MHz with frequency of operation. Performing voltage scaling also enables a seamless shift between power efficient (i.e., low power) and performance efficient (i.e., high throughput) computing tasks.
Another important challenge is to be able to support ML models that can learn directly on the device with very limited memory resources. This capability offers the desired privacy and security for many applications while also ensuring agile interaction with its environment. The approach to address this problem today is to train ML models in the cloud using deep learning models with tools such as Google’s TensorFlow and then convert these trained models into an inference model that operates at the edge.
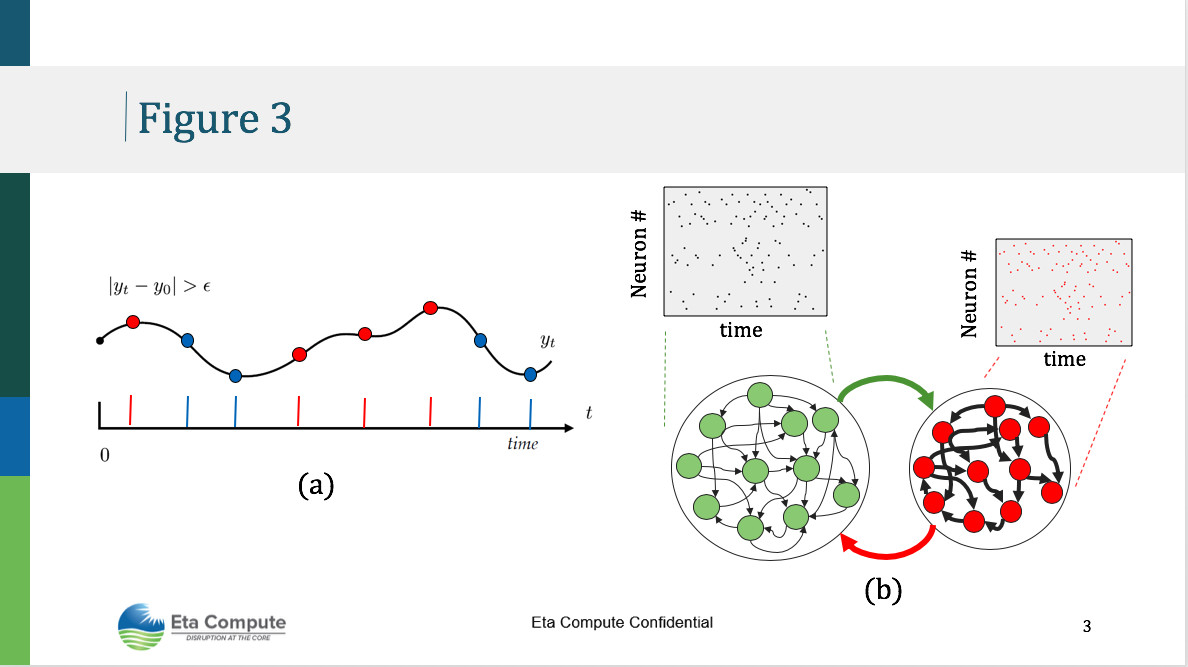
We are exploring a new approach based on principles of brain computing or neuromorphic computing [1] to be able to both learn directly from data streams but also do so with a limited number of training examples and with limited memory requirements to store the learned knowledge. The basic idea here is to represent data/signals (Figure 3) explicitly by incorporating time in the form of action potentials or spikes and then by combining the asynchronous mode of chip operation (as described above) with the asynchronous mode of learning using spikes. The spiking neural network (SNN) computations offer a very sparse representation of data and is very energy efficient to implement using DIAL because computing only happens when there are spike events. Furthermore, learning is enabled only using local learning rules with sparse connectivity and is thus not as parameter intensive as a traditional ML model thus saving on memory required to store and time needed to train the model [2]. The last but equally important aspect of SNNs is to exploit structural constraints (Figure 3) to encode memory of event sequences for rapid learning without the need for multiple data presentations during training. Combining these aspects of the model with a processor powered by DIAL results in an edge device that interchangeably can learn and infer thus enabling an agile sense-learn-infer-act model.
Eta Compute is developing real-world applications for pattern recognition using this technology and we discuss two such examples. The first is in continuous recognition of spoken digits using data from the Speech command dataset [3]. This dataset is composed of audio snippets of single digits from 2,300 different speakers for a total of 60K utterances. Our SNN was trained using a single pass of each training sample while achieving an accuracy of 95.2 percent on the test set comparable to other ML models. Our SNN model is orders of magnitude more efficient from a model efficiency point of view (as measured by the number of training samples needed and the number of network parameters to learn) while performing with comparable accuracy.
The SNN was also able to generalize to robustly identify digits in a continuous mode due to intrinsic short-term memory for robust detection of the beginning of 10-digit utterances even with overlapping spectrograms due to other digits. This model was ported onto our asynchronous Eta Core chip. The audio was captured from a microphone and digitized using our low power ADC on chip and the digitized signal was converted into spectrograms and then encoded into spikes using DSP. The ARM M3 performed SNN computations (Figure 4(a)). The total memory for the model was 36 KB. The total power consumed from data to decision (i.e., including I/O, DSP and M3) was 2 mW with an inference rate of 6-8 words/sec.
The same principles were applied to a handwritten digit recognition problem based on training data from the MNIST benchmark [4]. The binary images were directly converted into spikes by the DSP while SNN learning is performed on the M3 (Figure 4(b)). The chip achieved an accuracy of 98.3 percent on the MNIST test set and required 64 KB of memory. The solution required 1 mW of power from data to decision with a throughput of 8 images/sec.

These results are suggestive of the potential for realizing intelligent, agile and efficient edge devices to drive a rapidly expanding IoT market with over 25 billion devices coming into use by 2020 as predicted by the Gartner group [5]. The co-development of other infrastructure such as standards for interoperability of devices and 5G wireless technology could, for example, enable new fitness trackers to robustly detect user state such as falling asleep to then automatically switching off lights. The future appears to be marching toward a smart and distributed computing model powered by intelligent and efficient edge devices and Eta Compute is developing novel technology to play a key role in it.
References
1. C. A. Mead, Neuromorphic Electronics Systems, Proc. of IEEE, vol. 78, no. 10, pp. 1629-1636, 1990.
2. N. Srinivasa, and Y. K. Cho, “Unsupervised discrimination of patterns in spiking neural networks with excitatory and inhibitory synaptic plasticity,” Front. In Comp. Neuroscience, doi:10.3389/fncom.2014.00159, 2014.
3. P. Warden, ‘Launching the Google Speech Command Dataset’, https://ai.googleblog.com/2017/08/launching-speech-commands-dataset.html.
4. Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, Gradient based learning applied to document recognition. Proc. of IEEE, vol. 86, pp. 2278-2324, 1998.
5. Gartner Says 4.9 Billion Connected "Things" Will Be in Use in 2015, https://www.gartner.com/newsroom/id/2905717.
About the Authors:
Narayan Srinivasa, Ph.D., CTO of Eta Compute, is an expert in machine learning, neuromorphic computing and their applications to solve real world problems. Prior to joining Eta Compute, Dr. Srinivasa was the Chief Scientist and Senior Principal Engineer at Intel leading the neuromorphic computing group. Before Intel, he was the Director for the Center for Neural and Emergent Systems at HRL Labs where he led many programs in machine intelligence including DARPA SyNAPSE, UPSIDE and Physical Intelligence. Dr. Srinivasa earned his bachelor’s degree in technology from the Indian Institute of Technology, Varanasi, and his doctorate degree from University of Florida in Gainesville and was a Beckman Postdoctoral fellow at the University of Illinois at Urbana-Champaign.
Gopal Raghavan, Ph.D., CEO and Co-founder of Eta Compute, is an expert in engineering design and innovation for advanced technologies that solve the world’s toughest challenges. Prior to co-founding Eta Compute, Dr. Raghavan was the CTO of the Cadence Design Systems IP Division. Before Cadence, he co-founded Inphi Corporation (NYSE: IPHI), a company that set new standards for ultra-high bandwidth optical solutions. Before Inphi, he worked at Hughes Research and for Intel. Dr. Raghavan earned his bachelor’s degree in technology from the Indian Institute of Technology, Kanpur, and both his master’s and doctorate degrees in electrical engineering from Stanford University.



