
Uncovering Real-Time Bugs with Specialized RTOS Tools - Part 2
May 20, 2019
Blog

In this section, we?ll explore some of the common issues encountered by developers when using an RTOS and show how those can be detected and corrected.
RTOS-based Issues
In this section, we’ll explore some of the common issues encountered by developers when using an RTOS and show how those can be detected and corrected.
Stack Overflow:
In a kernel-based application, each task requires its own stack. The size of the stack required by a task is application-specific [1]. You are wasting memory if you make the stack larger than the task requires. If the stack is too small, your application will most likely write over application variables or the stack of another task. Any write outside the stack area is called a stack overflow. Of course, between the two alternatives, it’s better to overallocate memory for the stack than underallocate. You can thus reduce the chances of overflowing your stacks by overallocating memory. However, 25-50% additional stack space is all that is typically needed. Some CPUs, like those based on the ARMv8M architecture, have built-in stack overflow detection. However, that feature doesn’t help to determine the proper stack size; it just prevents the negative consequences of stack overflows.
Reference [1] explains how to determine the size of each task stack. In a nutshell, you start your design by overallocating space for your task stacks, then run your application under its known worst-case conditions while monitoring actual stack usage.
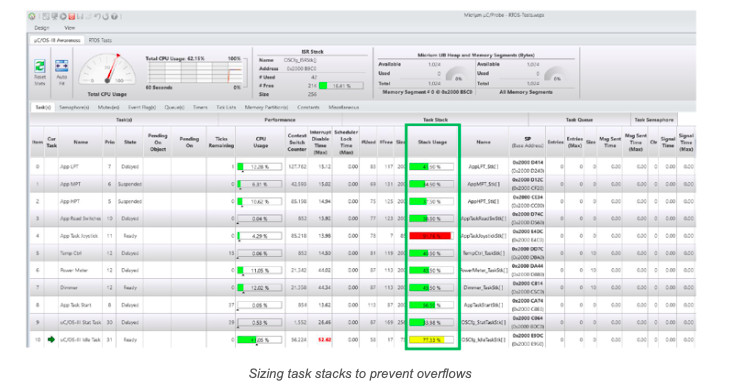
The figure below shows a screenshot of μC/Probe’s kernel awareness of a test application. The Stack Usage column shows a bar graph of the maximum stack usage at any given time for each task. Although a screenshot was taken, μC/Probe updates and displays this information live so you don’t have to stop the target to view this information as it’s being updated.
Green indicates that the maximum stack usage has been kept below 70%.
Yellow indicates that stack usage is between 70% and 90%.
Red indicates that stack usage has exceeded 90%.
Clearly, the stack for the task that uses 92% should be increased to bring it back below the 70% range. The task stack that is Yellow is the idle task, and, at 77%, it will generally not be an issue unless you add code to the idle task callback function (this depends on the RTOS you use).
Interrupt Response:
RTOSs and application code often have to disable interrupts when manipulating internal data structures (i.e., critical sections). RTOS developers make every attempt to reduce the interrupt disable time as it impacts the responsiveness of the system to events.
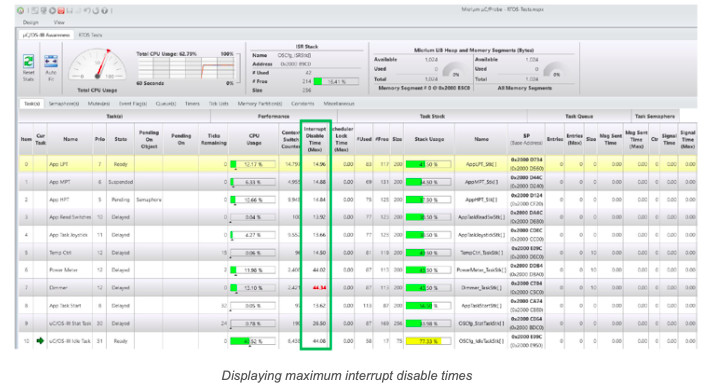
Some RTOSs actually measure the worst-case interrupt disable time on a per-task basis as shown in the μC/Probe screenshot below. This information is invaluable if you are trying to satisfy real-time deadlines.
The amount of time interrupts are disabled greatly depends on the CPU, its clock rate, your application and the RTOS service being invoked. The task that disables interrupts the longest is highlighted in Red. This allows you to quickly identify potential outliers, especially in large and complex applications.
If the largest interrupt disable time is caused by the RTOS, then you might not be able to do much about it except possibly:
- Find alternate RTOS APIs with lower interrupt disable times. For example, if you are only signaling a task to indicate that an event occurred, then you might simply suspend/resume the task instead of using a semaphore or event flag. In other words, the task waiting for the event suspends itself and the ISR that signals the event resumes the task.
- Increase the clock rate of your CPU. Unfortunately, this is rarely an option since other factors might have decided the ideal CPU clock frequency.
- Use non-Kernel Aware interrupts to handle your highly time-sensitive code.
Priority Inversions:
Priority inversion occurs when a low-priority task holds a resource that a high-priority task needs. The problem is aggravated when medium-priority tasks preempt the low-priority task while it holds the resource. The term “priority inversion” refers to the fact that a low priority task acts as if it had a higher priority than the high-priority task, at least when it comes to sharing that resource.
Priority inversions are a problem in real-time systems and occur when using a priority-based preemptive kernel (most RTOSs are preemptive). As shown in the diagram below, SystemView is used to illustrate a priority-inversion scenario.
App HPT (High Priority Task) has the highest priority
App MPT (Medium Priority Task) has a medium priority
App LPT (Low Priority Task) has the lowest priority
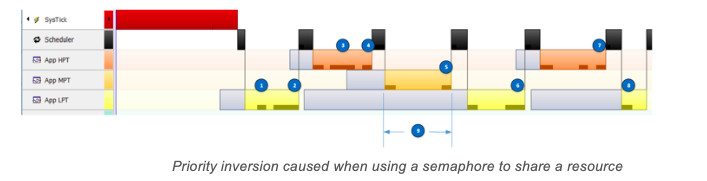
1 - The LPT is the only task that is ready-to-run, so it gets the CPU and acquires asemaphore to gain access to a shared resource.
2 - To simulate the occurrence of a priority inversion, the LPT makes the HPT ready-to-run, and, thus, the RTOS context switches to the HPT.
3 - The HPT makes the MPT ready-to-run but keeps executing because the HPT still has a higher priority.
4 - The HPT needs to access the shared resource and attempts to acquire the semaphore. However, since the semaphore is owned by the LPT, the HPT cannot continue executing, so the RTOS switches to the MPT.
5 - The MPT executes until it needs to wait for its event to reoccur so the RTOS switches back to the LPT.
6 - The LPT finishes its use of the shared resource, so it releases the semaphore. At this point, the RTOS notices that the HPT is waiting for the resource and thus gives the semaphore to the HPT and makes it ready-to-run. The HPT resumes execution and performs whatever operation it needs to perform on the shared resource.
7 - Once the HPT finishes accessing the resource, it releases the semaphore and then waits for its event to reoccur (in this case, we simulated this with a self-suspend).
8 - The LPT resumes execution since neither of the other two tasks are ready-to-run.
9 - The priority inversion occurs because an LPT holds a resource that the HPT needs. However, the problem gets worse when medium-priority tasks further delay the release of the semaphore by the LPT.
You can solve the priority inversion issue described above by using a special RTOS mechanism called the Mutex (Mutual Exclusion Semaphore). The figure below shows the same scenario, except here the LPT and HPT both use the mutex to gain access to the shared resource instead of a semaphore.

1 - The LPT is the only task that is ready-to-run, so it gets the CPU and acquires a mutex to gain access to a shared resource.
2 - To simulate the occurrence of a priority inversion, the LPT makes the HPT ready-to-run, and thus the RTOS context switches to the HPT.
3 - The HPT makes the MPT ready-to-run but keeps executing because the HPT still has a higher priority.
4 - The HPT needs to access the shared resource and attempts to acquire the mutex. However, since the mutex is owned by the LPT, the HPT cannot continue executing. However, because a mutex is used, the RTOS will increase the priority of the LPT to that of the HPT to prevent it from being preempted by medium priorities.
5 - The RTOS then switches to the LPT, which now runs at the same priority as the HPT.
6 - The LPT finishes its use of the share resource, so it releases the mutex. The RTOS lowers the LPT’s priority back to its original (lower) priority and assigns the mutex to the HPT.
7 - The RTOS switches back to the HPT since it was waiting for the mutex to be released. Once done, the HPT releases the mutex.
8 - Once the HPT finishes execution of its work, it waits on the reoccurrence of the event it is waiting for.
9 - The RTOS switches to the MPT, which was waiting in the ready queue.
10 - When the MPT completes its work, it also pends on the event that will cause this task to execute again.
11 - The LPT can now resume execution.
The priority inversion is now bounded to the amount of time the LPT needs to access the shared resource. Priority inversions would be very difficult to identify and correct without a tool like SystemView.
Note that you can use a semaphore if the LPT was just one priority level below the HPT. A semaphore is preferred, in this case, because it’s faster than a mutex since the RTOS would not need to change the priority of the LPT.
This blog is part 2 in a three-part series, to read part 3, click here.



