
MPU Security Part 4: Dynamic Regions, Debug, and Conclusions
May 10, 2019
Blog

This is the fourth part of a four-part series of articles presenting a unique product MPU Plus? and a methodology for using the Cortex-M MPU to achieve improved MCU security.
This is the fourth part of a four-part series of articles presenting a unique product MPU‑Plus® and a methodology for using the Cortex-M Memory Protection Unit (MPU) to achieve improved Microcontroller Unit (MCU) security. Part 3 presented partition problems including heap usage, function call APIs, interrupts, parent and child tasks, and task local storage. Part 2 presented partitioning, secure boot, MPU control, and system calls. Part 1 presented some introductory concepts: MMUs vs MPUs, increasing need for security, protection goals, MPU-Plus snapshot, Cortex‑v7M and v8M, and MPU operation.
Dynamic Regions
As noted previously, creating static regions is a time-consuming, tedious, and error-prone process. The dynamic data regions discussed below help to relieve some of this burden.
Dynamic Data Regions
The following functions allow dynamically creating data regions during initialization or from ptasks:
u8* mp_RegionGetHeapR(rp, sz, sn, attr, name, u32 hn);
u8* mp_RegionGetPoolR(rp, pool, sn, attr, name);
BOOLEAN mp_RegionMakeR(rp, bp, sz, sn, attr, name);
where rp is a pointer to the created region, sz is the region size, sn is the slot number, attr are the attributes, name is an optional name for the region, hn is the heap number, pool is a block pool handle, and bp is a block pointer. The above can be used to make a data region from a heap, a block pool, or a static block (e.g. stat_blk[100]), respectively.
Normally rp points to an entry in the dynamic protection region array, dpr[n]. Then, the MPA template slot for the dynamic region is set as follows:
mpa_tmplt_t2a[sn] = MP_DYN_RGN(dpr[n]);
where MP_DYN_RGN() loads the address of dpr[n] and sets the dynamic region flag in the template slot.
These functions should normally be called during system initialization before tasks start running. However, they can also be called by ptasks, which are creating and initializing other tasks.
Dynamic data regions can be used to store a mixture of static arrays and structures, and they can be shared between tasks. Although they cannot be used for global variables, they do save the complexities of defining sections in the code, blocks in the linker command file, and static regions in templates. Hence, they are simpler and less error prone to use. Given that sz is likely to be a sum of sizeof()’s they may also be more flexible during development.
Protected Data Blocks
The following protected block functions permit creating protected data blocks from either utasks or ptasks and also releasing them, while running:
u8* smx_PBlockGetHeap(sz, sn, attr, name, hn);
u8* smx_PBlockGetPool(pool, sn, attr, name);
BOOLEAN smx_PBlockMake(bp, sz, sn, attr, name);
BOOLEAN smx_PBlockRelHeap(bp, sn, hn);
BOOLEAN smx_PBlockRelPool(bp, sn, pool, clrsz);
where the parameters are the same as for dynamic regions, except that for the release functions, bp is the block pointer returned by one of the Get functions, and clrsz specifies how many bytes to clear after the free block link in the first word of the block. Basically, a block is obtained from a heap or a pool or made from a static block. A region is created for it and loaded into MPU[sn] and into MPA[sn] of the current task. The heap can be any heap, including the main heap. This is safe because if a hacker penetrates a task, the MPU prevents him from accessing heap memory outside of the protected block.
Dynamically allocated blocks can be used for buffers, work areas, messages (see below), or structures. If a task is written such that all of its static variables are in a structure, for example:
u8* vp;
vp->var1 = vp->var2 + vp->var3;
Then a dynamic block can be used to store its static variables. In the above, vp is the block pointer returned by the BlockGet() function. (Note that vp is an auto variable and thus is stored in the task stack, not in the structure). If a function is not written this way, it is not difficult to convert it -- just insert "vp->" ahead of every static variable reference, define a VP structure with the variable names as fields, and define vp as a pointer to VP.
The difference between a protected data block and a dynamic data region is that a protected data block can be obtained by a task while it is running, whereas a dynamic data region is created during initialization, and a pointer to it is loaded into a task’s template. Protected data blocks are especially useful for utasks to create temporary buffers and protected messages, as discussed below.
Using Dynamic Regions
Using a dynamic data region, a protected data block, or a TLS to replace the task_data static region requires redefining all task global variables as fields in one or more structures. If the structure name is very short, this does not appreciably complicate the code. For example, here is some code from eheap:
hvp[hn]->errno = EH_OK;
bsmap = hvp[hn]->bsmap;
csbin = hvp[hn]->csbin;
In order to support multiple heaps, it was necessary to change discrete globals to an array of structures, hvp[hn]. In this case, hvp[hn]-> was pasted to the start of every global variable name in the code. The Cortex-M architecture allows accessing structures as fast or faster than discrete globals – one LDM instruction in a function loads the structure base address and fields are accessed via constant offsets, thereafter. The compiler may not be able to do this for all discrete globals used by a function, hence access to them may be slower. Using a structure also allows grouping fields together that are used together, which improves performance if the processor has an instruction cache. Multiple structures and arrays can be handled automatically by using sizeof()’s to determine pointer offsets.
Protected Messages
An smx message consists of a Message Control Block (MCB) linked to a data block. The smx_MsgMake() function can be used to make a protected data block into a protected message and the current task becomes the message owner. Messages are sent to message exchanges and received from message exchanges. While at a message exchange, the message's MCB is linked to the exchange’s control block into a queue of waiting messages.
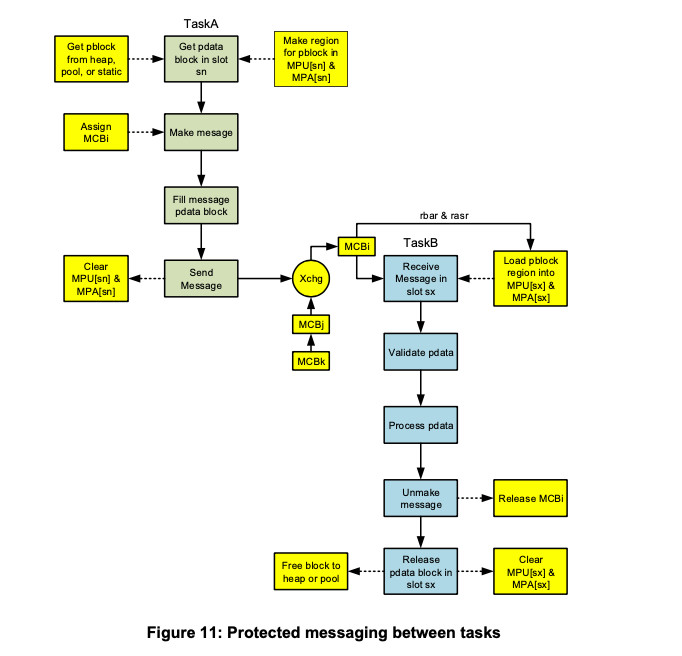
Figure 11 illustrates transferring protected messages between tasks. TaskA is shown in green and TaskB is shown in blue. Yellow represents pcode and pdata, which are protected from either task. As shown, TaskA gets a pdata block in slot sn, makes it into a message, loads it, and sends it to Xchg. As part of the send operation, slot sn in the MPU and in TaskA’s MPA are cleared. Note that other messages are waiting at Xchg and that MCBi is at the top of the message queue. TaskB receives it in slot sx. Note that rbar and rasr are obtained from MCBi and used to create the region for the message’s pdata block in slot sx. TaskB validates the message, which is application-dependent and might consist of doing range and consistency checks on the data. It then processes the pdata, unmakes the message, releases the pdata block in slot sx back to its heap or pool, and clears slot sx in the MPU and in TaskB’s MPA.
Two protected message functions have been added to smx:
MCB_PTR smx_PMsgReceive(xp, bpp, sn, timeout);
BOOLEAN smx_PMsgSend(mp, xp, sn, pri, rp);
Where xp is the exchange pointer, bpp is a pointer to the message block pointer, sn is the MPU/MPA slot number, timeout is in ticks, mp is the message pointer, pri is the message priority, and rp is a reply pointer (e.g. to the exchange to send a reply message.)
As shown in Figure 11, when a protected message is sent, its slot, sn, in the MPU and in the current task's MPA are cleared. Thus, even if the sending task retains a pointer to the message block (e.g. bpp), it cannot access the message block. This foils the hacking technique of changing a message after it has been validated by a receiving task in another partition. It also foils reading the message after it has been updated by a receiving task in another partition.
While at an exchange, the message block region information is stored in the message’s MCB, and the exchange is the owner of the message. When the message is received by a receiving task, its message block region information is loaded into the specified slot, sx, of the MPU and of the receiver's MPA and the receiving task becomes the message owner. (sx need not be the same slot as was used by the sending task.)
Now, the receiving task can read and modify the message and possibly send it on to another exchange. Hence, a message could be created, loaded with data, passed on to a task to check the data and encrypt it, and then passed on to a third task to send it over a network. Note that there is complete isolation between the sending and receiving tasks. Of course, the sender could send some kind of disruptive message. Hence the receiver must perform validation before accepting a message. This level of security is application specific.
Partition Portals
As discussed in Part 3, partition portals enable isolating client partitions from server partitions and are necessary to achieve 100 percent partition isolation, which is critical to achieve strong security. They are built upon the smx protected messages described above. Protected messages satisfy the Arm PSA Secure IPC requirement (see reference 3 in Part 1) without the need for message copying. Hence, introducing portals versus normal function call APIs may not degrade performance appreciably.
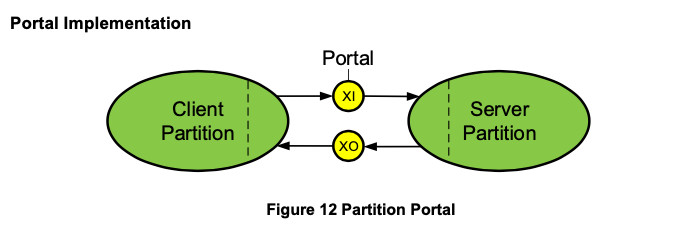
As shown in Figure 12, a partition portal consists of exchanges, marked XI and XO — one for each direction. Code added to the client partition (represented by the area to the right of the dashed line) converts function calls and their parameters into messages that are sent to the XI exchange. The client task then waits at the XO exchange for a reply message.
A server task, in code added to the server side (represented by the area to the left of the dashed line), is waiting at the XI exchange for a message. When it receives a message, it converts it to a function call using parameters in the message. It then puts return information from the function call into a message that it sends to the XO exchange. The client task receives the message from the XO exchange and returns information to the caller in the client partition.
Clearly there is quite a bit of work to convert function call interfaces between partitions to partition portals. However, the result is strong partition isolation. This, of course, comes at a reduction in performance. Data buffers are passed in messages. If existing code is being modified, this may require copying data from buffers to messages and vice versa. If new code is being created, it can be designed to work with messages in no-copy mode. In the latter case, the performance hit may be minor.
Note that the data copy problem also exists in large MMU-based systems. In fact, in that case there is not a no-copy solution because of virtual address spaces. Hence, inter-partition communication via portals in MPU-based systems can be more efficient than inter-process communication in MMU-based systems. This favors smaller partitions, each of which do less work, and thus system security is potentially better. Having smaller partitions also makes redundant paths more practical – e.g. two independent paths to report suspicious activity back to headquarters.
Debug Support
Debugging code is much more challenging when security features are enabled. For this reason, SecureSMX allows overriding most security features during early code development and debugging to help speed up these phases. Security features can be reenabled during later-stage debugging where they actually become helpful by detecting stack and buffer overflows and other problems. Also, it is advisable to start addressing security issues before development has gone too far.
smxAware™ includes many security-related features to help debug MPU-Plus based software. It displays the current MPU and all task MPAs, with named regions. The graphical Memory Map Overview shows MPU regions in the memory bars. Start and end addresses, as well as excluded subregions are shown. In all displays, errors such as alignment and overlap are flagged. For more information, see:
smxAware User's Guide, by Marty Cochran and David Moore, Micro Digital Inc.
Conclusions
Software engineering has lost its naivete – we are now designing for a hostile world. It is not possible to achieve perfect security, but it can be pretty good. A determined hacker will no doubt find some weakness in even the best security you can devise. It therefore is necessary to analyze all of your code versus probable threats.
In some cases a body of code may be so poorly designed and implemented and thus so vulnerable, that reworking it is a hopeless proposition. In that case it may be more cost-effective to leave the code as is and to put it into a fully isolated umode partition, using the methods described in this article. Then it is necessary to devise a strategy to deal with the inevitable break in and to implement the necessary code to handle it. In the process, some latent bugs may be found.
If upgrading legacy code to improve the security of an existing product or if developing a new product using legacy code, the main job is generally to restructure the legacy code. The amount of recoding that is required can be small, depending upon how well the code is structured to begin with. New code, of course, should be structured for security from the outset.
Security adds another dimension to product development. It is necessary to think not only about how to implement a function but also to think about how a hacker might gain access to the function in order to cause damage or to steal private data. MMFs are annoying during debugging, but they prove that the hardware security mechanisms actually work! The goal of MPU-Plus is to provide a path that will accomplish good security without excessive anguish.
This is the end of this series. For more information see www.smxrtos.com/mpu and check back for future updates.
Ralph Moore is President of Micro Digital. A graduate of Caltech, he has served many roles at Micro Digital since founding it in 1975. Currently he is lead architect and programmer for MPU-Plus, eheap, and smx.



