
LDPC FEC is becoming the preferred technology in wireless backhaul
November 05, 2014

Increasing data rates combined with limited spectrum are requiring technologies like LDPC FEC to help keep pace. The interest of the wireless industry...
Increasing data rates combined with limited spectrum are requiring technologies like LDPC FEC to help keep pace.
The interest of the wireless industry in forward error correction (FEC) with low-density parity check (LDPC) codes has surged over the last few years. In the era of Gigabit-per-second transmission rates and physical limitation of a channel capacity, every useful information bit has a value on its own. LDPC FEC has proven to be an efficient system component in increasing transmission robustness at very incremental cost. According to Cisco’s VNI index, we should be prepared for a more than 10x increase in annual run rate of data traffic by 2018. Under that scenario, every element of the telecom network has to be designed with high efficiency, and this will apply specifically to wireless data transmission, which has limitations associated with the availability of spectrum resources.
The theoretical maximum channel capacity follows the famous theorem introduced by Claude Shannon back in 1948. According to his theorem, codes exist that enable operations in a noisy channel arbitrarily close to the theoretical channel capacity. This formulation has since spiked a lot of interest and practical work around searching for codes enabling operations near Shannon capacity.
Interestingly, such efficient codes were already proposed in 1963 by Robert G. Gallager in his seminal doctoral thesis Low Density Parity Check Codes. It was about this time when Reed-Solomon and Bose-Chaudhuri-Hocquenghem (BCH) codes were introduced, and long before Turbo codes came into being. However, LDPC FEC required high computational complexity by using multiple iterations of codeword bit estimates in conjunction with reasonably large matrices, and hence at times when these codes were proposed, they didn’t find any practical implementation.
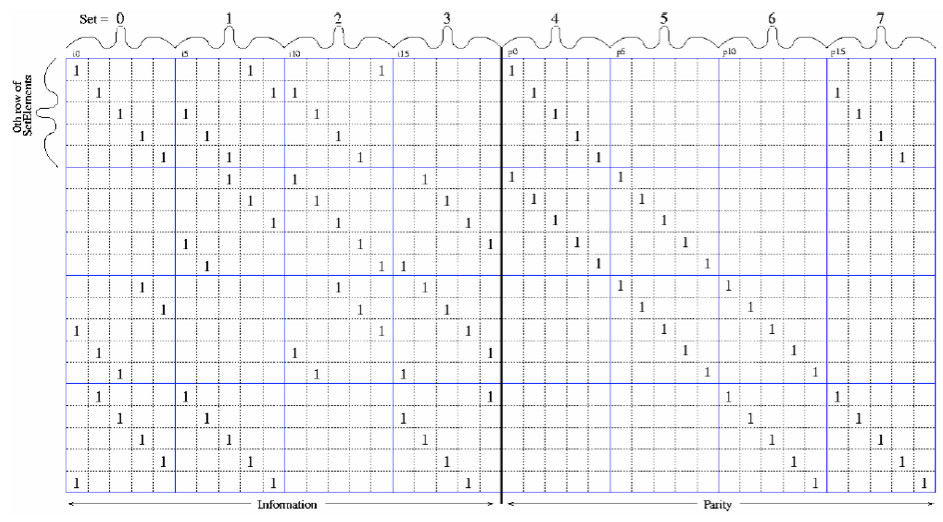
LDPC codes are linear with a sparse parity check matrix. These belong to the class of block codes designed to include low density “ones” in rows and columns of the parity check matrix. The intention behind using sparsely distributed parity check architecture is to apply probabilistically independent XOR calculations, whereby the estimates of parity check values are aggregated across each row of the parity check matrix and every subsequent iteration improves the estimates. Many tens of iterations may be required before the estimates converge and all the errors are corrected. The exact number of iterations, however, is determined by the code designer based on the application and specifications of the system a particular code needs to operate in. Numerous trade-offs are possible before determining the minimum number of iterations required to meet the specs of a particular system. Modern LDPC FECs work with soft decision algorithms, further enhancing decoder gain.
With larger block length N, the confidence level in the error correcting capability increases. However, it increases the computational complexity by increasing the size of the parity check matrix and thereby increases the number of calculations required to estimate each bit (Figure 1).
|
|
Another problem with using large blocks and iterations is increased latency, as those computations are made on a block-by-block basis. With limited processing and memory resources, this would become a critical constraint in using LDPC codes in latency sensitive applications, such as voice communications. Another example is the Hybrid Automatic Repeat Request (HARQ) propagation time requirement in 3GPP-LTE, which limits the roundtrip time to 5 ms, and delays introduced by baseband user equipment processing would consume a significant part of that latency budget. With new Cloud RAN architectures and wireless being considered for the front haul, this latency budget becomes critical in planning design limitations around FEC used in the wireless modem, which is often the largest latency contributor in the entire signal processing chain.
Actual commercial breakthrough in adopting LDPC FEC in wireless communications happened with the introduction of the DVB-S2 satellite broadcasting standard back in 2003. The use of LDPC FEC over convolutional coding used in the previous DVB standard increased threshold gains by roughly 3dB and enabled migrating to higher spectral efficiency. Seven to eight years later, LDPC FECs were making inroads into wireless backhaul links, where higher spectral efficiency was becoming an important design goal with the advent of 3G and the subsequent data traffic explosion and backhaul bottleneck challenges. Now, it’s the de facto standard in backhaul wireless link design.
The design of powerful LDPC FEC codes is still a complicated task due to the same limitations that were there 50 years back. Naturally, hardware platforms where those codes can be implemented have made a huge jump during this time and, even though the computational power has increased tremendously, the designs have to be power and cost efficient plus be integrated with most of the other functional blocks that are responsible for communication. Additionally, bandwidth requirements have increased significantly and now we will need to be able to process higher throughput. Therefore, when designing LDPC codes, one needs to balance between myriad different optimization exercises in determining the architecture to preserve good performance at low latency, low power consumption, and low cost. These design choices are connected with the capabilities of underlying hardware platforms, since some of those are better suited for LDPC FEC implementation than others.
Unlike DSPs, FPGAs offer highly parallel structure for the type of computations required by LDPC encoders and decoders. The IP is highly configurable and lets the user choose different levels of parallelism to optimize the decoder size and also customize the solution to support a variety of channel bandwidths. The LDPC FEC is scalable and supports narrow microwave bands (3.5 to 112 MHz) to truly wide millimeter wave bands (250 Hz to 1,000 MHz). The so-called multi-layered coding technique simplifies LDPC FEC architecture and keeps the size of the code base and power consumption feasible for use on low-end FPGA platforms.
The special X-decoding algorithm used in Xilinx’s FEC code achieves significant SNR gain already with a low number of iterations, which in turn results in better decoder latency. Figure 2 showcases an example performance of LDPC FEC codes, as compared to RS FEC. On average, there’s a 2 to 4 dB improvement over RS codes depending on the code rate, codeword length, and number of iterations. The example below uses low coding overhead at high data rates.
|
|

The FEC is typically implemented in conjunction with the wireless modem and packet processing blocks on the same FPGA to benefit from complete baseband integration. Often, due to platform agnostic design practices and legacy ASIC conversion, those designs tend to be too big to benefit from the adoption of reasonably priced FPGAs. This design challenge is addressed by Xilinx’s 1+Gbps LDPC FEC encoder and decoder SmartCORE IP, enabling the use of the FEC IP together with modem and packet processing.
The research in LDPC will continue and we can expect that the codes will find even more applicability in different communication scenarios. It’s likely we will see the adoption of low density parity check techniques in newer generations of CMTS and data center systems. But they will likely show up in future 5G standards, where the use of higher frequencies and single-carrier waveforms are being reviewed.




