
The push to process vehicle sensor data
November 09, 2017

There are many semiconductor vendors and technologies jockeying for position in the race to process vehicle sensor data.
Continued from: "Advanced image sensors take automotive vision beyond 20/20."
And there are many others now in the race to process all of that vehicle sensor data. Among them, Toshiba has been evolving its Visconti line of image recognition processors in parallel with increasingly demanding European New Car Assessment Programme (Euro NCAP) requirements.
Starting in 2014, the Euro NCAP began rating vehicles based on active safety technologies such as lane departure warning (LDW), lane keep assist (LKA), and autonomous emergency braking (AEB). These requirements extended to daytime pedestrian AEB and speed assist systems (SAS) in 2016. In 2018 the requirements will expand further to include nighttime pedestrian AEB, as well as day and nighttime cyclist AEB (Figure 1).

Figure 1. European New Car Assessment Programme (Euro NCAP) requirements have expanded in recent years to include many advanced driver assistance system (ADAS) functions.
To meet the demand for vision systems that can accurately identify both mobile and stationary objects in daytime and nighttime settings, image recognition processors like Toshiba’s TMPV7608XBG Visconti4 processor incorporate a suite of compute technologies (Figure 2). In addition to CPUs and DSPs, eight hardware acceleration blocks allow the device to efficiently execute highly specialized automotive computer vision (CV) workloads, such as affine transformation (linear mapping), filtering, histograms, matching, and pyramid image generation.

Figure 2. The Toshiba TMPV7608XBG Visconti4 image recognition processors leverage CPUs, image processing engines (DSPs), and image processing accelerators (hardware accelerators) to compute a range of automotive computer vision (CV) workloads.
Two new hardware acceleration blocks on the TMPV7608XBG specifically address the challenges of nighttime and mobile/stationary object detection: the enhanced co-occurrence histogram of oriented gradients (CoHOG) and structure from motion (SfM) accelerators.
For nighttime ADAS applications, the enhanced CoHOG accelerator goes beyond conventional pattern recognition by combining luminance- and color-based feature descriptors that offset the low contrast between objects and their surroundings. According to Toshiba, Enhanced CoHOG accelerators not only reduce the time required for object recognition, but result in pedestrian detection that’s as reliable at night as it is during the day.
Meanwhile, the SfM accelerator uses sequential images from a monocular camera to develop three-dimensional estimates of the height, width, and distance to an object (Figure 3). Stationary objects can therefore be detected without any learning curve, and motion analysis and pattern recognition can be applied to detect moving objects such as pedestrians or vehicles. Because the three-dimensional information reduces the region of interest within an image, ADAS systems are able to recognize and react to obstacles more quickly.
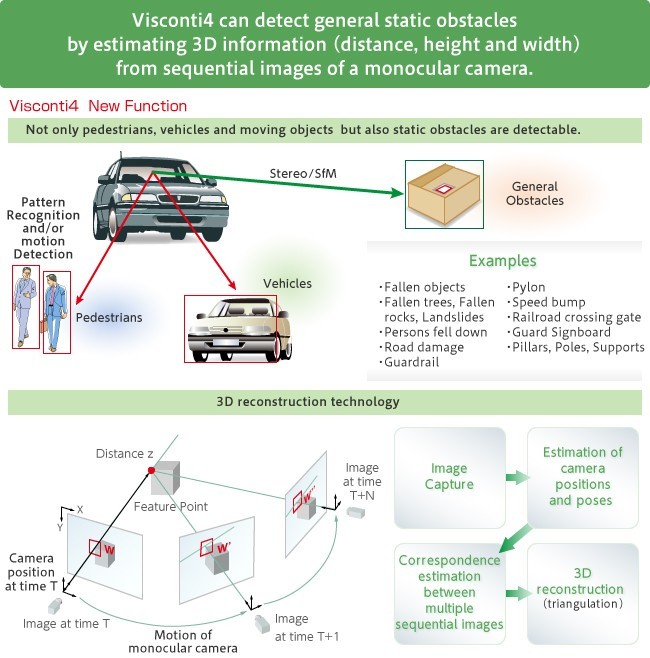
Figure 3. The TMPV7608XBG’s structure from motion (SfM) accelerator uses three-dimensional mapping to detect both stationary and mobile objects.
These accelerators operate in conjunction with eight media processing engines (MPEs) in the TMPV7608XBG’s DSP subsystem, each of which are equipped with double-precision floating-point units (FPUs). As a result, the device can simultaneously execute eight image recognition applications in parallel with a response time of 50 milliseconds (Figure 4). Running at clock frequencies of 266.7 MHz, this represents a 50 percent reduction in processing time compared to previous Visconti processors (Figure 5).
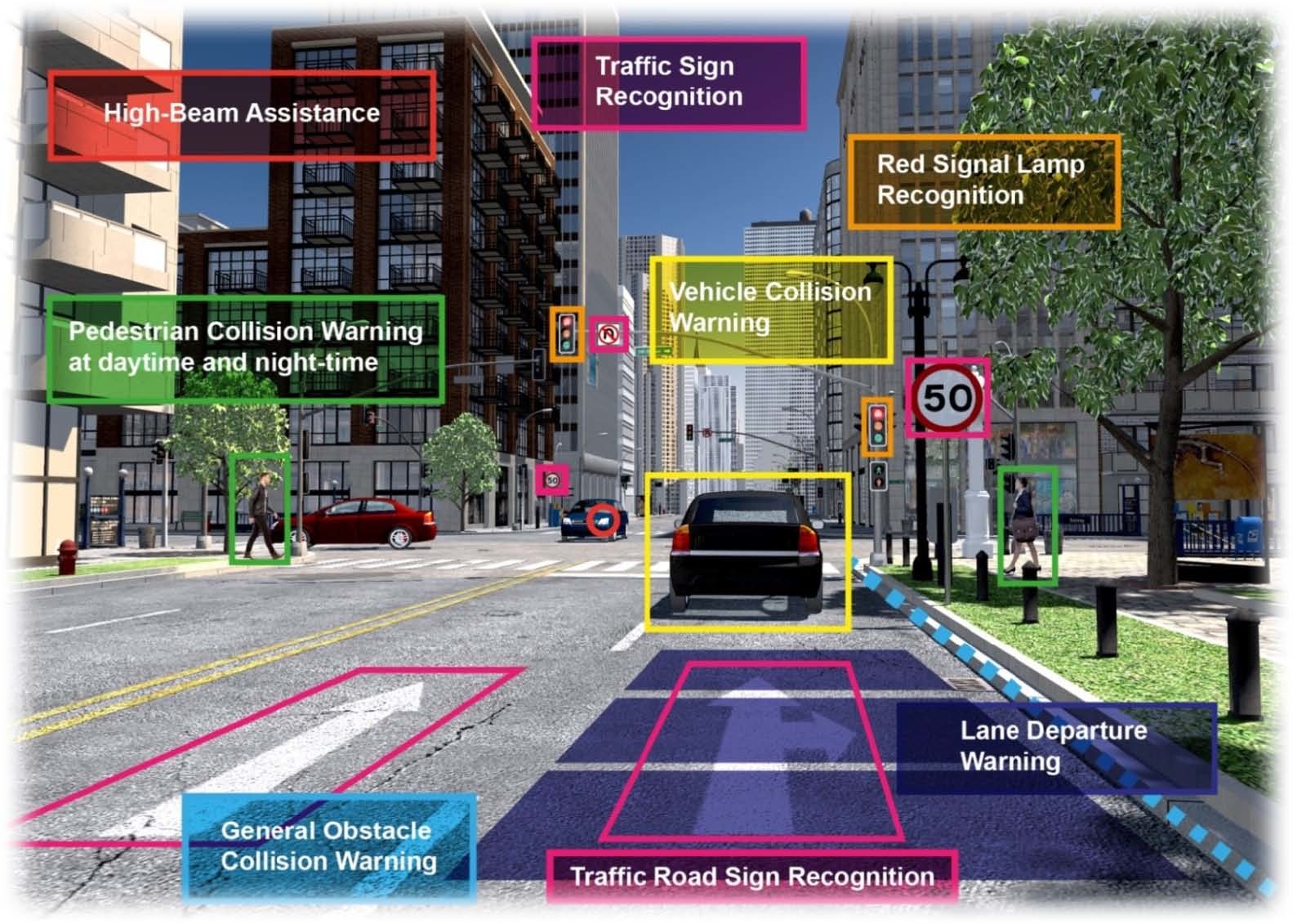
Figure 4. The TMPV7608XBG Visconti4 processor equips eight media processing engines alongside hardware acceleration blocks to enable eight simultaneous image recognition applications with 50 millisecond response times.
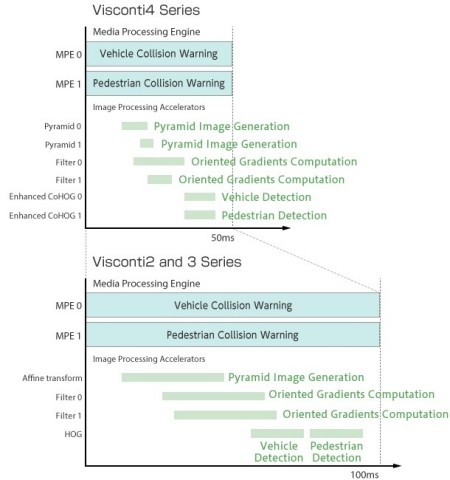
Figure 5. The performance of TMPV7608XBG Visconti4 processors represents a 50 percent reduction in processing time over previous-generation Visconti processors.
Toshiba’s publicized design wins for Visconti4 image recognition processors include a front-camera-based active safety system from DENSO Corporation.
AI and autonomous drive’s call for compute
But image processing is just one piece of the puzzle in today’s automotive safety systems. Modern ADAS applications and semi-autonomous vehicles rely on inputs from radar, LiDAR, proximity sensors, GPS, vehicle-to-everything (V2X) connectivity, and other active components, in addition to cameras. Data from all of these inputs must be processed, analyzed, and fused in real-time so that corrective action can be taken quickly in hazardous situations.
Artificial intelligence (AI) would appear the ideal technology to enforce driving policies and make real-time decisions in autonomous and semi-autonomous vehicle use cases. However, conventional cloud-based implementations of AI are unsuitable in automotive safety applications, largely because of the latency associated with data transmission, but also due to privacy, security, cost, and network coverage issues.
As an alternative, supercomputer-class processors capable of running on-chip artificial or deep neural networks (ANNs/DNNs) are being designed into the electronic control units (ECUs) of automotive safety systems in cars like Teslas. For example, NVIDIA claims that variants of its Drive PX Pegasus platform (available in 2H 2018) will provide up to 320 trillion deep learning operations per second (TOPS), which is considered more than sufficient for level 5 autonomous vehicles (Figure 6).
Figure 6. Supercomputer-class processors from companies such as NVIDIA have the processing power to fulfill a range of fully autonomous driving requirements.
Unfortunately, these processors come with challenges of their own. Aside from considerable power consumption and cost per unit, the die size of these chips is enormous (Figure 7). If factoring in one such processor for each of the roughly 100 million cars produced every year, the automotive market would demand three times the silicon currently produced for smartphones. This far outstrips current silicon wafer manufacturing capacity.
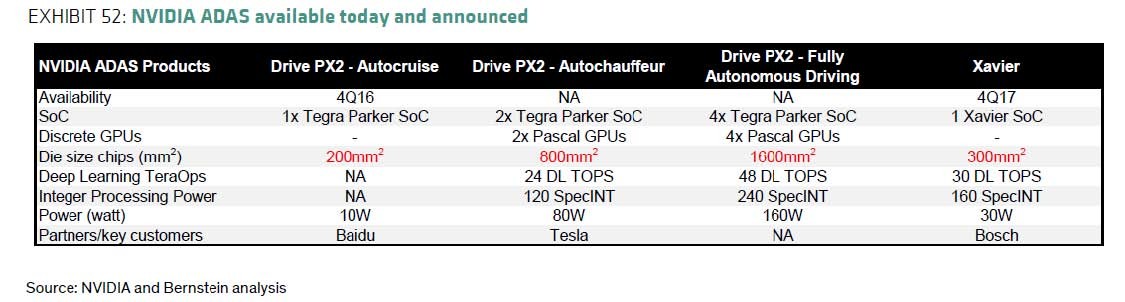
Figure 7. While high-performance processors provide the computational horsepower to run on-chip neural networks for fully autonomous driving, the die size required to produce them currently outstrips silicon wafer manufacturing capacity. Source: NVIDIA and Bernstein Research.
Again, DSP IP blocks offer a solution that’s more optimized for embedded automotive use cases, with the CEVA Deep Neural Network (CDNN) providing an example. CDNN includes a neural network generator, software framework, and hardware accelerator that are tailored to work with CEVA-XM imaging and vision DSP cores (Figure 8). The value proposition here is reduced power consumption, lower cost, and the ability to distribute intelligence throughout a system design.
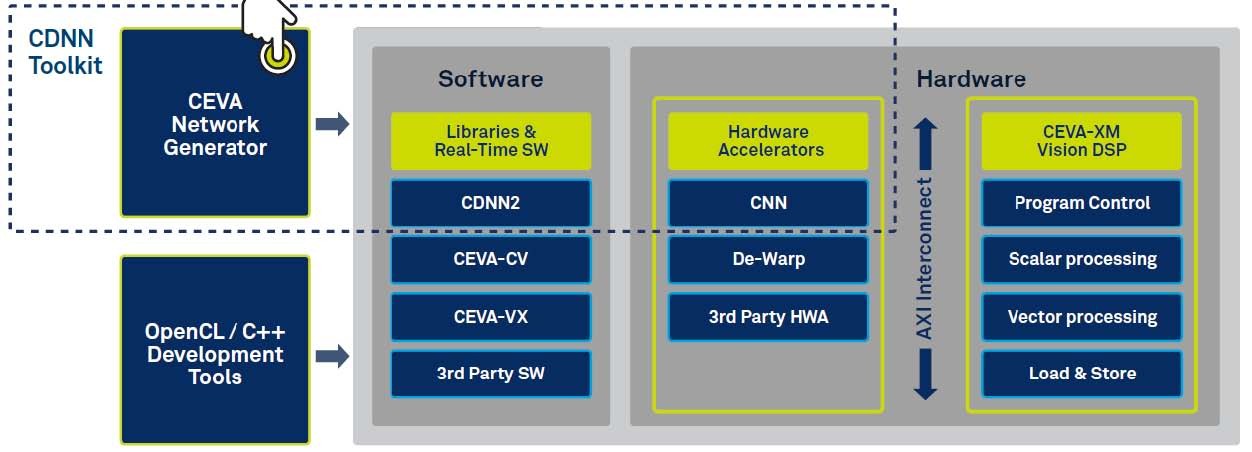
Figure 8. The CEVA Deep Neural Network (CDNN) is a toolkit for developing, generating, and deploying neural networks on embedded DSPs.
Central to CDNN are DSPs like the CEVA-XM6, which includes vector and scalar processing units and a 3D data processing schema. The vector and scalar processing units make the -XM6 well suited for sensor data fusion, while its 3D data processing scheme helps accelerate neural network performance (Figure 9). In the CDNN context, these DSPs are accompanied by one or more hardware accelerators that deliver 512 multiply-accumulate (MAC) operations per cycle in convolutional neural network (CNN) processing. All other neural network layers – of any type or number – are run by the DSP itself.
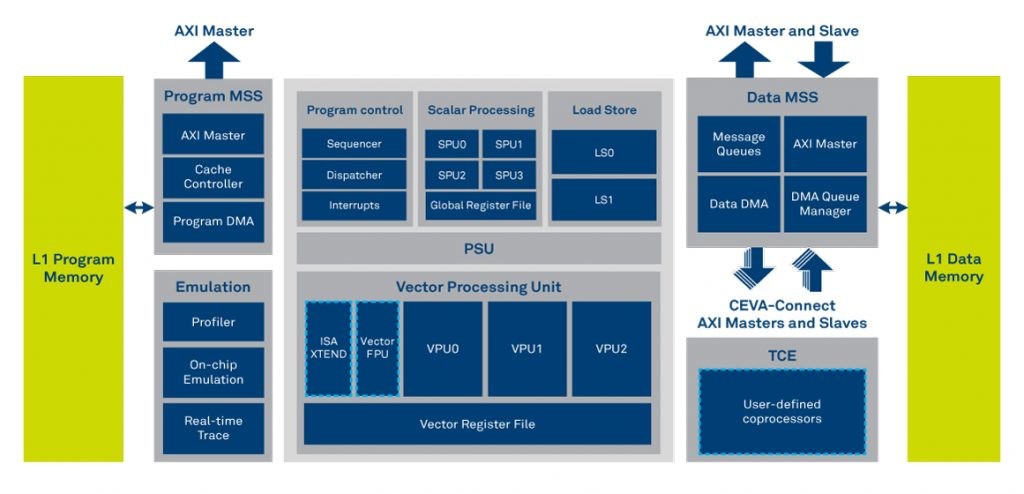
Figure 9. Vector and scalar processing units combine with a 3D data processing scheme to make the CEVA-XM6 DSP well suited for automotive safety and artificial intelligence workloads.
But what makes the CDNN toolkit unique is the CEVA Network Generator. The Network Generator converts pre-trained neural networks developed in frameworks such as Caffe and TensorFlow into real-time neural network models that can run in embedded systems (Figure 10). From there, the second-generation CDNN Software Framework can be used for application tuning.
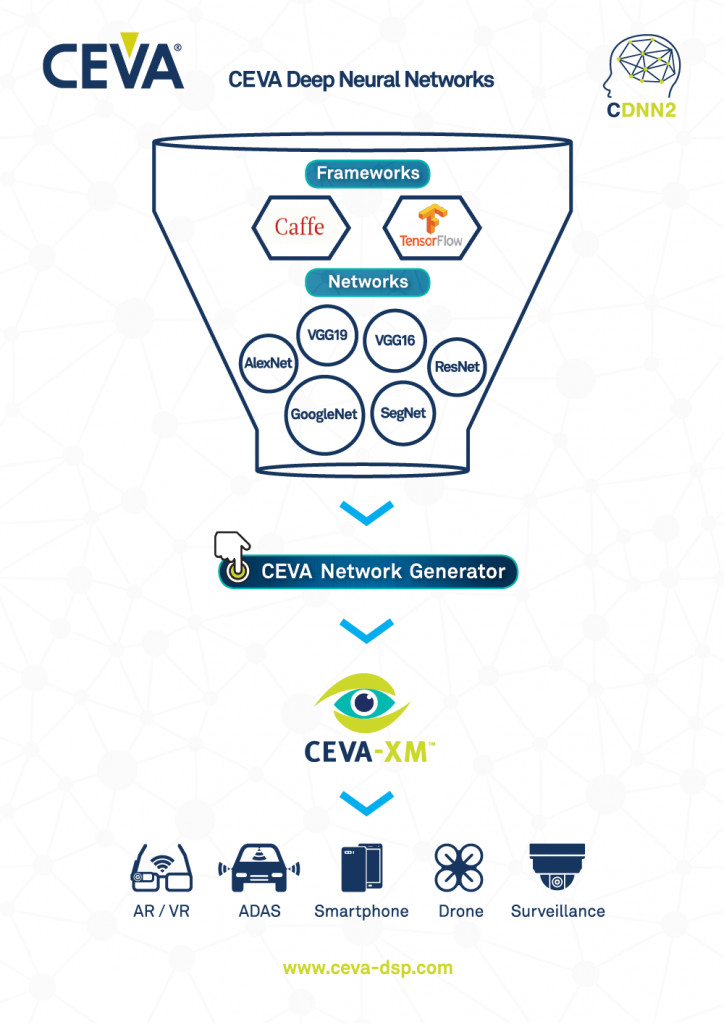
Figure 10. The CEVA Network Generator is an offline tool that converts pre-trained neural networks developed using frameworks like Caffe and TensorFlow into real-time neural networks for embedded systems.
According CEVA, Inc., the CDNN toolkit processes CNNs four times faster than GPU-based alternatives at 25x the power efficiency. Richard Kingston, the company’s Vice President of Market Intelligence, Investor, and Public Relations said that the technology currently has more than five design wins in the automotive space, with notable partners being ON Semiconductor, NEXTCHIP, and a tier one automotive OEM who is using it in a fully autonomous vehicle design.
Continue reading: "Connectivity puts precision into automotive positioning."



