
How Flexibility, Accessibility & AI Helped Xilinx Beat 2020
July 07, 2021
Story

In what may come as a surprise given all of the recent turbulence in electronics markets, Xilinx, the supplier of programmable logic device technology, reported growth across several of their core business units.
According to Victor Peng, CEO of Xilinx, this includes high single-digit growth in their industrial, science, and medical (ISM) markets thanks to wins in COVID-19 vaccine research equipment and platforms like the Mars Perseverance rover. It's also the result of double-digit growth in automotive sales last year, where more than 80 million units shipped on the strength of demand for advanced driver assistance systems and autonomous driving features.
How was Xilinx able to sustain its growth trajectory when so many others faltered?
"When you need high throughput performance – and when you have some degree parallelism you need high throughput performance – and you also need good latency response – in some cases, indeed real-time, where you can’t just batch it all up and do it offline – those things are really good for us," Peng explains. "Also, when you have a need for not just one thing that you do over and over again, but you’re going to optimize things over time and there’s a lot of change because there are new innovations you want to deploy over time. Or because you want to swap out different kernels, you want to accelerate different things. Those kinds of applications we’re really, really good at."
Most in the tech sector already knew that about programmable hardware in general, and Xilinx in particular. The company has been developing FPGAs that support these requirements for decades, and Arm-based FPGA SoCs that do the same for years.
For context, Intel stayed the course with its core technologies in 2020 and saw losses in Q3 and Q4. The difference, at least in part, may have to do with the Xilinx’s emphasis on edge AI capabilities.
"Back in 2018, we talked about how the world is becoming smart and connected, and smart in this case is not just having some sort of microprocessor or microcontroller but actually embedding AI into a lot of these applications. Things are scaling out all over the place, the pace of innovation is increasing, and the end of Moore’s Law, the data explosion, and so on and so forth," Peng continues.
"We’re unique in a sense that because of our flexibility we could accelerate a pretty wide range of AI, but also the non-AI portions," he says. "Most applications are not just completely AI, they’re doing lots of other processing and they have multiple neural networks embedded in them. Automotive is a classic example, but there are many more.
"So, we coined the term ‘whole application acceleration’ because it’s really unique in that a lot of people are doing specialized chips that accelerate a small class of neural networks but they don’t really accelerate other kinds of processing and I think it’s really a unique competitive advantage of ours that we can accelerate a broad range of AI, as well as other non-AI processing, so we really deliver whole application acceleration," Peng adds.
Adaptive Compute for Whole Application Acceleration
Now, for a little bit more context.
Xilinx’s new 7 nm Versal VLIW/SIMD tiled architecture, which integrates an AI engine, improves ML inferencing performance by 20x in GoogleNet image classification while consuming 40 percent less power than its 16 nm Xilinx UltraScale+ predecessor (Figure 1).

Figure 1. The Xilinx Versal platform's integrated AI engine delivers a 20x inprovement in image classification performance over previous-generation Xilinx devices at 40 percent less power. (Source: Xilinx)
The increases shown in Figure 1 stand up to the competition as well. Xilinx's new Versal devices demonstrate a 20x performance improvement executing Google Speech commands over the NVIDIA V100, and an almost 3X uptick in throughput on Resnet-50 workloads compared the NVIDIA Tesla T4, per benchmarking data from partner Numenta (Figure 2).

Figure 2. The Versal architecture also stands up to competitive offerings from NVIDIA, demonstrating significant throughput advantagges over NVIDIA's Tesla T4 and other platforms. (Source: Xilinx)
Versal is part of the company’s Adaptive Compute Acceleration Platform, or ACAP, a line of multicore heterogenous compute engines that provide scalable performance and power consumption by coupling FPGA fabric, DSP blocks, and other programmable cores with high-bandwidth memory and SerDes connections via a Network on Chip (NoC).
"On the same piece of silicon with our architecture you get factors of improvement, and you don’t get this with other architectures," Peng says. "If you get 20 percent, 30 percent [improvement] on software applications with a fixed architectures, that’s pretty good. No one gets 3x with the same piece of silicon.
"But you actually can do this with our architecture."
There is enough performance headroom in the architecture that Peng and his team plan to keep the Versal product line at its current process node, 7 nm, for the foreseeable future. This includes next-generation Versal ACAP devices and potentially beyond, but many workloads will require performance improvements well before that.
"You’re going to get the traditional, significant performance boost when we do this next generation of silicon architectures," the Xilinx CEO notes. "But before those silicon architectures come out, you can get significant performance boost from things like overlaying domain-specific architectures. You could also do things like what Numenta and others are doing: really novel, innovative ways to compress and accelerate neural networks.
"Everybody is doing quantization with different data types and sparsity, and there is a lot of richness in what you could do," he goes on (Figure 3). "So, the key takeaway here is we absolutely have a road map of how we’re going to evolve the AI engine architecture over next generation silicon, but in the meantime we and our partners will rapidly innovate and drive performance even higher through things like sparsity."

Figure 3. The Versal ACAP architecture permits performance improvements beyond process node enhancements, for example through support for domain-specific architectural enhancements enabled by its compute flexibility. (Source: Xilinx)
Advancing Edge AI: Beyond Compute Performance
But as Peng notes, it’s not all about sheer compute performance.
"I really hate how, especially in AI, everybody is infatuated with TOPS because what is limiting to the performance of AI is more often the data and the data movement and the memory," he asserts. "And so, the other thing that is unique about us is we let you customize the data movement, the memory, and the memory path. That gives you true, sustained performance, not peak TOPS numbers. And ultimately, if you do a good job, you’re more power efficient, more energy efficient."
But despite these technical advantages, so often it’s not as much about simply having a superior technology as superior usability – just look at the Windows operating system and the iPhone: Many would argue that these are not the "best" technologeis in their respective technology categories.
Recently, Xilinx addressed the need for exceptional usability in non-traditional ways for a semiconductor company.
"We’ve been moving up the abstraction stack," Peng states. "Our customers that are experts in RTL, we’ll continue to add value to them. But we’re also giving them some options to develop at a higher level of abstraction, and we can also help enable people who traditionally haven’t used those platforms: application developers, AI developers, data scientists, and so on.
"I like to use the term accessibility and not just talk about ease of use because ... what I mean by accessibility is not just the experience of the development environment, but having access to lot of different optimized libraries; using languages that people are familiar with that aren’t hardware developers; interfacing to standard frameworks like PyTorch, TensorFlow, Caffe, and so on; and also driving ecosystems.
"It’s that entire menu of things that make it a much easier platform to develop, and I think we’ve made a lot of strides on all those fronts, certainly with Vitis as far as a single development environment," the tech executive states (Figure 4).
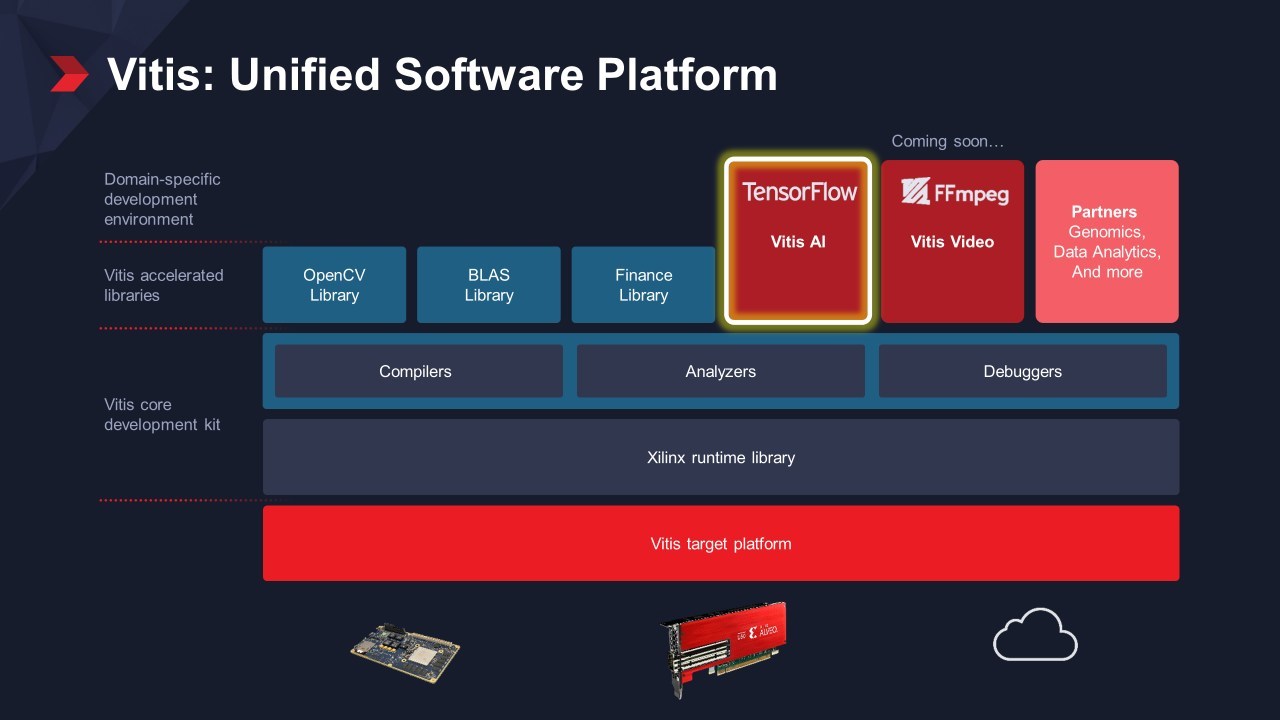
Figure 4. Xilinx's Vitis software development environment supports traditional RTL programming as well as higher levels of abstraction for application developers, domain-specific engineers, and others. (Source: Xilinx)
However, Xilinx' accessibility extends beyond the Vitis software development environment, as the organization has ventured into the business of hardware modules – first with smart NICs and data center acceleration cards, but more recently with embedded hardware platforms like KRIA that have been designed for use cases like edge AI and machine vision (Figure 5).

Figure 5. Xilinx KRIA hardware modules like the KV260 AI Vision Starter Kit are part of the company's strategy to make Versal technology more accessible to the broadest range of developers and engineers, as well as OEMs and systems integrators. (Source: Xilinx)
"You’re going to see more of that, and I think this is a win-win because our customers can still differentiate it with our cards, but now we’re giving them closer to a complete solution, and, in a few cases, a complete solution," Peng remarks. "That helps their time to revenue, and it helps our time to revenue. I would also say that I think it really helps people that maybe don’t have the expertise to get down to the hardware level to optimize everything.
"They can get more of that complete solution and, in a sense, this helps expand our user base," he adds.
Opportunity Abounds in AI
All of these factors have contributed to Xilinx' strong performance in AI sockets and, based on the company’s growth, obviously in the market as well.
So what's the ceiling? Now that much of the turbulence from the last couple of years appears to be slowing, it sounds like Peng thinks there might not be one.
"The size of the opportunity at the edge is larger even than the data center, even though the data center opportunity is very large. One of the things I’ve always thought to be so exciting for me personally being at Xilinx and now joining up with AMD ... is that we really have the opportunity to play in both those areas, end-to-end. And we do. A lot of people talk about it we’re actually, really end-to-end in all those areas, and all those areas are growing.
"I know I’m not directly giving you a number, but I’m telling you characteristics of the workload and I think that’s an expanding workload," he offers. "CPUs are great at procedural stuff and they have some degree of parallelism, structural parallelism with threads and cores, but that peaks out at some point.
"You couldn’t be in a more exciting time in the industry right now, exactly because the old way of doing things is just not going to cut it. People aren't looking for 20 to 30 percent improvement, they’re looking for 10x, 100x, 1000x improvement.
"The need for compute is just about infinite today. Then when you fix the compute, you have a storage issue and you have a network bandwidth issue. So I think it’s really exciting we play in all those areas," Peng concludes.

Tiera Oliver is the assistant managing editor at Embedded Computing Design. She is responsible for web content editing, product news, and story development. She also manages, edits, and develops content for ECD podcasts, including Embedded Insiders.
She utilizes her expertise in journalism and content management to oversee editorial content, coordinate with editors, and ensure high-quality output across web, print, and multimedia platforms. She manages diverse projects, assists in the production of digital magazines, and hosts company podcasts by conducting in-depth interviews with industry leaders to deliver engaging and insightful discussions.
Tiera attended Northern Arizona University, where she received her bachelor's in journalism and political science. She was also a news reporter for the student-led newspaper, The Lumberjack.



