Smarter IoT Endpoints Enabled by Artificial Intelligence at the Farthest Edge
July 25, 2019

The World Wide Web recently turned 30, a milestone that passed with surprisingly little fanfare. Perhaps because the internet as we knew it then is a bit like the Wright Brothers? first flight ?...
The World Wide Web recently turned 30, a milestone that passed with surprisingly little fanfare. Perhaps because the internet as we knew it then is a bit like the Wright Brothers’ first flight – the technology is so very different to what we have now that it pales by comparison. What is comparable is their disruptive impact and, in that respect, Artificial Intelligence (AI) is shaping up to be even more impactful than powered flight or democratized data. The advances being made in AI right now are redefining what we will consider possible for years to come.
The new internet is the Internet of Things (IoT) and it’s all about data – generated and processed at a scale simply inconceivable before the IoT. Now, through applying AI to that data, we can achieve dramatically improved insights. AI can now identify leaks in London’s water grid so engineers can target precise pipeline replacements. It can measure how people using Tokyo’s Shibuya crossing at peak times impacts traffic flow. And it can measure how New Yorkers react to that new advert in Times Square. Three examples, three industries – utilities, logistics and marketing – all enhanced by AI.

The amount of data currently being collated by the IoT is already huge, but it’s set to get far bigger and far more interesting. In February 2019, Gartner said that the adoption of artificial intelligence in organizations is tripling year on year. For engineers and engineering companies, increasing intelligence in the device network means we can start to realize the true potential of the IoT.
Where AI will be most useful in the Industrial IoT (IIoT)
AI is quickly becoming a task that can be handled by mainstream computing resources; we already have AI, in the form of machine learning (ML) inference, running on single-sensor devices such as asthma inhalers. We can access AI-driven photo enhancement directly on our smartphones, and then there are the computer vision apps running in advanced vehicles. All of these are already improving lives, but I think we’ll see the most immediate commercial value in industrial applications.
In an industrial environment, any technology that can increase productivity is valuable, and operational data is routinely used to deliver insights into machines and their current condition. The data generated by industrial sensors contain patterns, which through increasingly sophisticated analytics, can help predict when an asset will fail, allowing it to be repaired before that failure has a bigger overall impact on productivity. This branch of predictive and preventive analytics has previously been carried out in large servers and ‘the cloud,’ but developments in AI and ML means it is now moving closer to the edge of the network. In fact, it’s being put directly into the machines that make up the IIoT.
Machine Learning at the Edge
There are many reasons why ML processing is moving to the edge. The first is the simplest to accept: the edge is where the data is created. There are other more critical reasons though; most notably because data consumes resources both in terms of bandwidth to move and instruction cycles to process. If all of the data being generated across the IoT were to be processed by servers, it would involve huge volumes of network traffic and an exponential increase in server power. It’s exactly why the likes of Google are slimming down some of their algorithms – so they can run independently of the cloud, on edge AI-powered devices.
Just as embedding an HTML server in an edge device is now commonplace, it is just as feasible to execute ML in an endpoint, such as a sensor. But the way ML will be implemented at the edge is crucial and it follows the concept of distributed processing. The processing resource required to train an AI algorithm is considerable, but it is effectively a non-recurring expense. The resources needed to execute inference models are more modest, but in volume can consume just as much – if not more – processing resource as the training phase. How they differ is that, unlike training, each instance of inference can be packaged and executed in isolation from all others, which means it can easily be ported to smaller processing resources and replicated as many times as required.
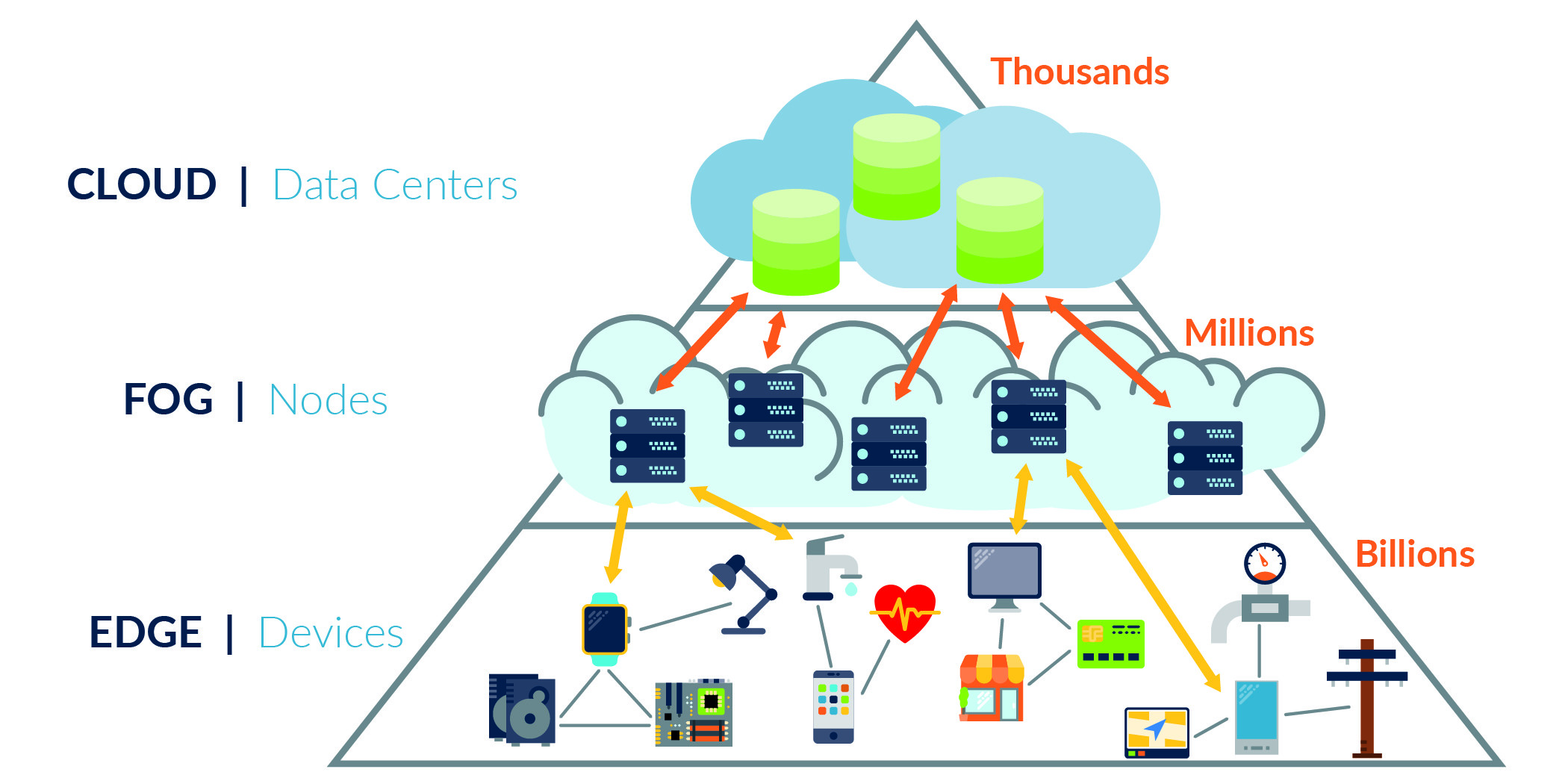
This distributed intelligence is the shape of the new internet, one that can operate in isolation once more if necessary, while remaining part of the whole. Edge processing removes the need to pass data across an increasingly congested network and consume ever-more valuable processing resources.
Architectures for ML
Once training is complete, AI frameworks provide the route to deployment. For resource-constrained devices being deployed at the edge, this includes the likes of TensorFlow Lite and Caffe2. These and other such platforms are typically open source and often come with a ‘get you started’ introduction; models that are already trained to provide some form of inference. These models can also be retrained with custom data sets, a process called transfer learning, which can save many hours of processing time.
In order to be portable across different processing architectures, the models typically run through an interpreter and are accessed by the host software using APIs. Because the models are optimized, the whole implementation can be made to fit into the low 100s of kilobytes of memory.
There are numerous examples of how ML is running on, at or near the edge of the network, and many of these will be running a Linux-based operating system. These CPU-based ML solutions use what are essentially general-purpose microprocessors, rather than the power-hungry and often large GPU-oriented devices that are common in desktop computers. GPUs have highly parallel execution blocks and make use of multiple MAC units, designed to carry out repetitive, math-oriented operations as fast as possible with little regard for the power consumed. They are often difficult to program, require high levels of power and are in general not suitable for resource-constrained edge devices.
TensorFlow Lite was designed to run some TensorFlow models on smaller processors, with pre-trained models available that can provide various types of ML, including image classification, object detection and segmentation. These three types of models work in slightly different ways: image classification works on the entire image, while object detection breaks the image up into rectangles, but segmentation goes further to look at each individual pixel. To use trained TensorFlow models in a TensorFlow Lite deployment, the models need to be converted, which reduces the file size using optional optimizations. The converter can be used as an API for Python, the code example below demonstrates how it is used.
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
tflite_model = converter.convert()
open("converted_model.tflite", "wb").write(tflite_model)
Running ML on standard processors means developers can also take advantage of simple software solutions based on industry-standard languages such as Python. These processors may feature DSP extensions in some cases, and these can be instrumental in accelerating parts of the data flow, but essentially general-purpose processors can handle the levels of processing required to run ML in smaller devices, while still dealing with the general application code.
CPU-led AI is already commonly used in smartphones, for identifying particular features in photos, for example. The same is true in industrial applications, where System on Chip (SoC) solutions based on multicore processors like the i.MX family from NXP are routinely being used to put ML into industrial processes. This includes machine vision systems that can identify specific products as they progress through a manufacturing process. These SoCs and others like them are perfect examples of how ML is being deployed today.

Moving beyond the horizon
While CPU- or MCU-led AI is commonplace now, we are already looking forward to the farthest edge of the device network where size, power, and cost requirements are ultra-constrained. This is where the latest version of TensorFlow comes in: TensorFlow Lite Micro, or TF Lite Micro as it’s called, is a version of the framework that has been designed to run on microcontrollers with perhaps no operating system, rather than microprocessors running Linux. The code and model together only need 45kbyte of Flash, and just 30kbyte of RAM to run. This is inference at the farthest edge, in a device operating completely autonomously without any assistance from any other software or, just as importantly, additional hardware.
The process of using TF Lite Micro is similar to using TensorFlow Lite, with the additional step of writing deeply embedded code to run the inference. As well as including the relevant .h files in the code, the main steps comprise: adding code to allow the model to write logs; instantiating the model; allocating memory for the input; output and intermediate arrays; instantiating the interpreter; validating the input shape, and actually running the model and obtaining the output. The code snippet below is an example of how to obtain the output.
TfLiteTensor* output = interpreter.output(0);
uint8_t top_category_score = 0;
int top_category_index;
for (int category_index = 0; category_index < kCategoryCount;
++category_index) {
const uint8_t category_score = output->data.uint8[category_index];
if (category_score > top_category_score) {
top_category_score = category_score;
top_category_index = category_index;
}
}
In order to support ML on microcontrollers, Arm has developed the CMSIS-NN software library, part of the Cortex Microcontroller Software Interface Standard (CMSIS) that deals with neural networks. Through quantization, which reduces floating point numbers down to integers (a process that has been proven to result in little or no loss of accuracy), CMSIS-NN helps developers map models to the limited resources of a microcontroller.
Super-efficient ML frameworks such as TF Lite Micro, along with CMSIS-NN, make it possible to use ML running on an ultra-low power microcontroller. This clearly has many possible applications, but one scenario that is very applicable to always-on systems is where the majority of the system remains in a deep sleep mode until a specific condition brings it to life, such as a wake word. We can think of this as a new kind of interrupt service routine, one that uses intelligence to decide when the rest of the chip/system needs to get involved. This clearly demonstrates the potential that ultra-low power ML functionality has to make a huge impact at the edge.
Moving forward, technology developments focused on the needs of edge inference will enable highly responsive and extremely capable ML models to run at even lower power levels. As an example, Arm has developed new vector extensions to the ArmV8-M architecture, called Helium. This is the latest development of the Arm Cortex-M processors, which gained the benefits of Arm TrustZone for security when the Armv8-M architecture was introduced in 2015. The development of the Helium vector extensions will combine NEON-like processing capability with the security of TrustZone. Helium vector extensions will also deliver a significant performance boost to Cortex-M class microcontrollers that will help enable many new applications, with even more responsive and accurate ML at the edge. Helium will deliver up to a 15x improvement in ML in Cortex-M devices, and as much as a 5x improvement in signal processing.
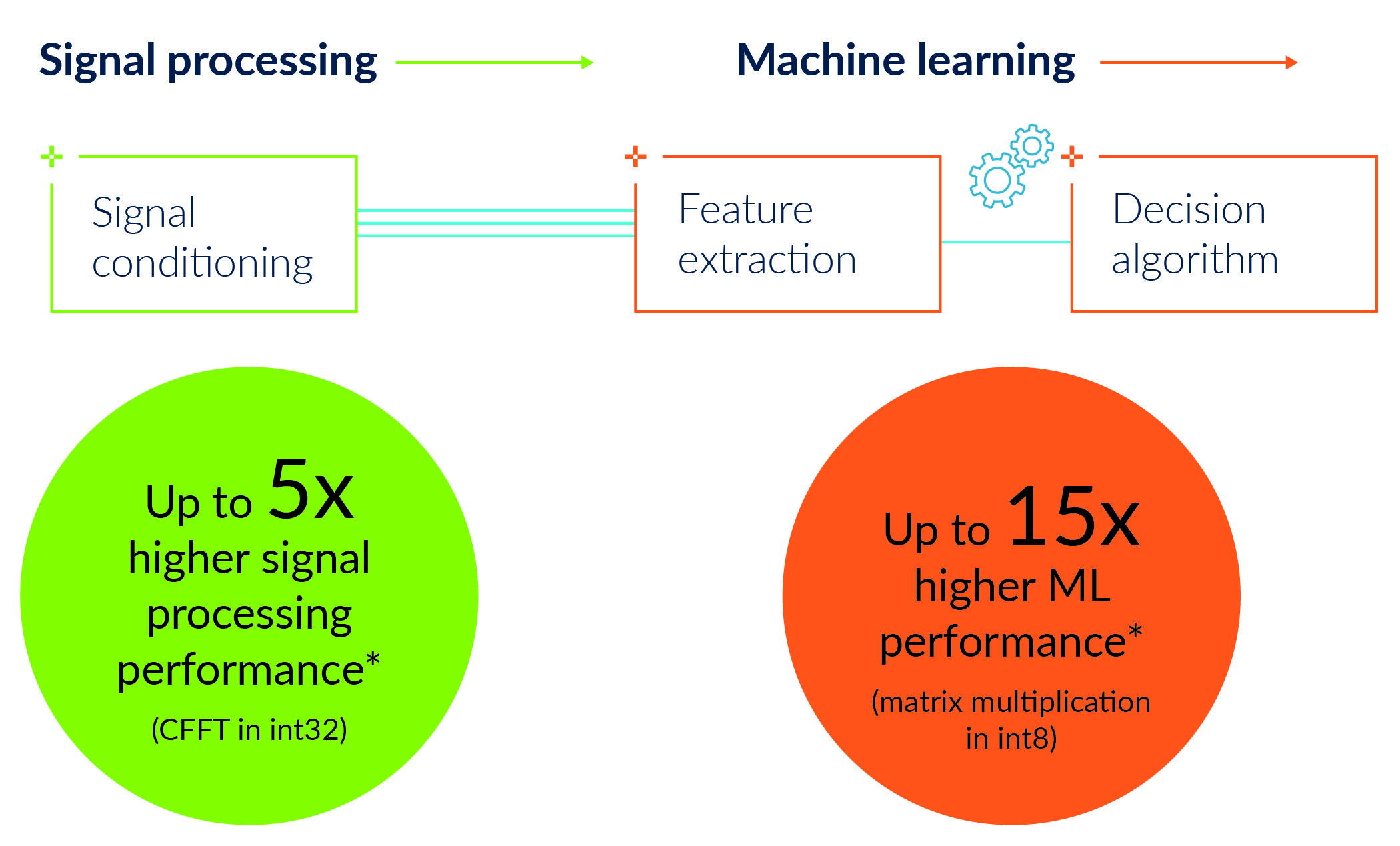
Just as importantly for developers, this means they will have access to ML in the same toolchain they use for other microcontroller-based developments. Integrating functions such as identifying unusual vibrations, unexpected noises or alarming images will be implicit in the control code, streamlining the entire process of putting ML at the edge. The toolchain and models are already available for early evaluation, with first silicon expected to be available by 2021.
Far from being “technology for technology’s sake,” the use of machine learning at the edge of the network is increasing due to demand for more responsive and robust control systems that aren’t dependent on cloud services and having an always-on connection to the IoT.
Using inferencing at the edge to limit the amount of data transferred over increasingly congested networks will be essential, if the IoT is going to scale to the trillions of devices we now realize will be needed to meet growing expectations.
Chris Shore | Director, Product Marketing | Arm
Chris has worked at Arm for over 18 years, currently as Director of Product Marketing in the Automotive and IoT group. Before that, he spent 18 months in the Enterprise Marketing team, responsible for the technical content of Arm’s conferences, including TechCon and the Annual Partner Meeting. For 15 years, he was responsible for Arm’s customer training activity – delivering over 200 training courses every year to Arm’s customers and end users all over the world. He also managed Arm’s Active Assist onsite services and the Arm Approved partner program.
Chris is a regular speaker at conferences and industry events and has addressed audiences on Arm technology on every continent except Antarctica – opportunities there are limited but it is surely only a matter of time!
Chris has lived and worked in Cambridge for over 30 years. He holds an MA in Computer Science from Cambridge University, is a Chartered Engineer and a member of the Institute of Engineering and Technology (MIET).