
Redressing the Balance in Codec Technology for High Definition Voice Applications
February 13, 2019
Blog

The continued and widespread digitalization that is taking place throughout the industry vividly illustrates that we now represent the world in an increasingly binary way.
The continued and widespread digitalization that is taking place throughout the industry vividly illustrates that we now represent the world in an increasingly binary way. It isn’t difficult to appreciate why; binary is the most effective format we have devised for handling data, and it now underpins all areas of technology.
The focus on digital makes it easy to forget that analogue is also just another way of representing information; the word itself really just means ‘comparable to.’ The perceived absence of quantisation in analogue tends to be obscured by the fact that an analogue signal ‘feels’ like the real thing. And while it is present, it is an area where technology continues to advance.
However, as long as it remains impractical to store, transfer or otherwise represent things such as sounds, sights, smells and textures in their native format, we will continue to rely on transducers to turn real-world information into a data form we can work with, whether that is analogue or digital.
The ubiquitous nature of Analogue-to-Digital and Digital-to-Analogue converters (ADC, DAC) is a clear reminder that we must move between the two domains. Conversion takes many forms and the wide variety in ADC and DAC architectures available reflects the differing needs for accuracy, repeatability and stability in the conversion(s) based on the needs of the specific application. This can present a challenge to engineering design teams when shortlisting converters for a given application.
One area where there is perhaps less confusion is the processing of voice data. In general terms, processing audio and video data involves the use of a CoDec, or Coder-Decoder; a class of data converter that is optimised for applications that operate on analogue and digital data containing signals associated with audio and video, including voice.
The move to multimedia
Any kind of transducer introduces an element of quantisation as by its very nature it is interpreting – rather than faithfully copying – information from one form to another. Typically, the primary output of a transducer will be electrical in nature, presenting a measurable change in resistance, capacitance or reluctance. For this reason, a transducer is also a type of filter, as it ignores some input levels in favour of others. Because the shape of audio and video information can vary hugely in terms of bandwidth and frequencies, codecs are designed to focus on the characteristics of the native signal.
Telephony is a well-established application area for codecs, as they provide the analogue/digital interface between both microphones and speakers. However, in more recent times semiconductor manufacturers have focused on developing and advancing codecs for multimedia signals rather than purely voice. The advent of the smart phone and tablet has occupied the industry’s attention when it comes to codecs, which isn’t surprising given that it represents an application area that offers potentially huge volumes in comparison to the pure voice market. Unlike a traditional voice device such as a telephone, the codecs used in portable consumer devices typically need to handle multiple types of data. The lure of the portable multimedia application area has meant investment in more traditional voice codecs has reduced over recent years. This has left OEMs with little choice when developing products that are voice-oriented; use a multimedia codec or base new products on voice codecs that are perhaps a decade or more old.
This fails to recognise the needs of emerging applications for purely voice-based products, such as mobile radio, wired telephony, voice-controlled equipment or public/private intercoms. It also inhibits the potential for manufacturers of these devices to exploit the benefits of modern transducers, which would ultimately enable smaller, lower power and higher performing solutions.
Voice codecs in profile
The incumbent voice codec will likely be designed to interface to a traditional electret microphone. These produce a small analogue signal that needs pre-amplification before it reaches the codec. Existing voice codecs may not integrate the necessary ADCs and DACs required to digitise the voice data, which means more external components. In addition, the codecs may not include an output power amplifier, which again means additional circuitry. Lastly, the codecs will most likely be manufactured using a legacy process node, which would indicate that ultra-low power isn’t a feature. Together, these drawbacks make existing solutions unsuitable for modern applications, where the need is for a voice codec that is small, low cost but highly integrated, and delivers high performance while consuming low power.
However, as well as influencing the development of codecs, the rise of the portable multimedia device has also contributed to huge developments in sensors based on Micro Electro-Mechanical Systems, or MEMS. The most prominent MEMS sensors are accelerometers and gyroscopes; the sensors that allow portable and wearable devices to discern their orientation and other movement. As they are based on the same technology, MEMS microphones are smaller and use much lower power than a traditional microphone, while offering improved overall performance and the integration of much more functionality. This removes the need for a lot of external circuitry, while creating an opportunity for codecs that can take full advantage of this development in technology.
Another area where technology has really moved on in recent years is the Class D amplifier. In essence, this is an analogue amplifier that operates in the digital domain, its name echoes other forms of amplification (such as Class A, Class AB). Class D amplifiers are a perfect complement to MEMS technology but have, until relatively recently, been complex and therefore difficult to implement. However, the efficiency gains offered by a Class D amplifier have encouraged the industry to pursue this area and we are now at a point where Class D amplifiers are becoming mainstream.
The new generation of voice codec
To address the lack of investment in the face of a growing need for dedicated voice codecs suitable for the latest applications, CML Microcircuits has developed the CMX655 family.
Designed specifically to support voice applications targeting both standard telephony and High Definition voice, they integrate a number of advanced features including the ability to interface directly to analogue and digital MEMS microphones. This makes the CMX655 family more optimised than general-purpose multimedia codecs and existing voice codecs, both in terms of functionality and power efficiency. The CMX655 family offers high audio quality and easier system design than existing voice codecs, thanks to its support for MEMS microphones and the integration of a Class D output amplifier, which is able to deliver up to 1W of power to a speaker.
The block diagram in Figure 2 shows the digital variant of the CMX655D, illustrating the major functions, including the digital microphone interface, the Class D amplifier and the audio signal processing block. The device can interface to two digital MEMS microphones simultaneously, enabling advanced features such as noise cancelation.
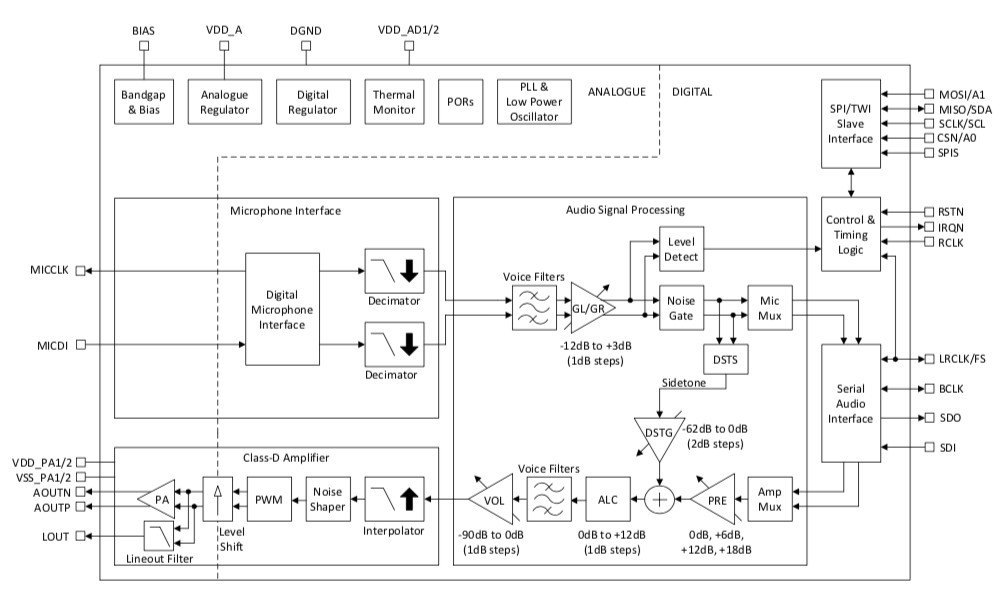
Typically, a MEMS microphone provides a serial output that complies with either the Pulse-Density Modulation (PDM) or Inter-IC Sound (I2S) protocols, both of which use a single digital signal to encode analogue data, which is synchronised with a clock. Both protocols can inherently support multiple microphone signals on the same bus, which is reflected in the design of the CMX655D by its ability to process two independent but fully synchronised microphone signals at the same time.
In a digital output MEMS microphone the initial conversion takes place inside the device and typically combines pre-amplification with PDM modulation. The output is then processed by the codec, which begins by converting the PDM bitstream into framed data. This involves the use of decimation filters to recover the low-frequency data from the high-frequency PDM signal. While this can be performed using a DSP, the software algorithms involved can be complex, the cost of the DSP relatively high and the overall power consumption considerable. Integrating this function as a hardware block in the codec promotes simpler design, lower system power and reduced BoM cost. As an example, the CMX655D consumes just 300µA in listening mode, a feature that is increasingly common in modern applications where the system is listening for an event, such as a wake word in a digital assistant, or the sound of breaking glass in a security system. In these applications, ultra-low power operation is an important feature.
The level of integration offered by the CMX655D means OEMs can now develop products with a much simpler signal chain, as most of the functions required are integrated into a single device. It supports bandwidths for both conventional telephony (300Hz to 3.4kHz) and HD voice (50Hz to 7kHz), which will enable a new wave of devices that can provide HD-quality voice. This includes telephones, PMR (Private Mobile Radio) and public/private intercom systems. Its low power credentials also make it suitable for security and fire alarm systems, voice-controlled consumer devices and wearable applications that need to remain ‘always-on.’ This is where the ultra-low power of the CMX655D will be a real differentiator compared with existing voice/multimedia codecs.
Conclusion
Voice codecs have been hugely underserved by the semiconductor industry for some time, leaving OEMs with little choice but to either use a more complex and expensive multimedia codec, a voice codec that can’t support the latest MEMS technology, or to implement the signal processing in software.
With the introduction of the CMX655 family of HD voice codecs, CML is redressing the balance by offering OEMs the ability to use cutting-edge technology in voice applications. With variants for both digital and analogue MEMS microphones, the CMX655 family of voice codecs has the potential to enable a new generation of voice-based products that meets modern consumers’ expectations.
Richard Walton is an Applications Engineer with over 20 years of experience working in the electronics industry. At CML, Richard is a member of the global applications team providing first line support to design engineers. Digital voice products are Richard’s speciality, covering the myriad voice coding methods available down to basic voice A-D/D-A conversion. Richard’s spare time is completely consumed by his family and he particularly likes a good family bike ride.



