
From Data to Drain: How AI Is Devouring the World’s Electricity
March 04, 2026
Blog
America’s data centers managed to keep their electricity use surprisingly steady from 2005 to 2017, with rather small annual increments contained via constant improvement in electronics. Then, around 2017, AI arrived forcefully and disrupted that stability.
AI required a different computing machine, one designed not for ordinary tasks, such as our beloved PC, but for gigantic mathematical workloads. Data centers began filling up with specialized processors called GPUs, originally built for graphics in video games but perfectly suited to compute huge amounts of math needed to train AI models. These processors are astonishingly powerful, but they are also voracious energy consumers.
By 2023, this shift had doubled the electricity use of U.S. data centers compared with just a decade earlier. Analysts from the IEA and Gartner suggest that by 2030, data centers could consume as much electricity as Japan or Germany.
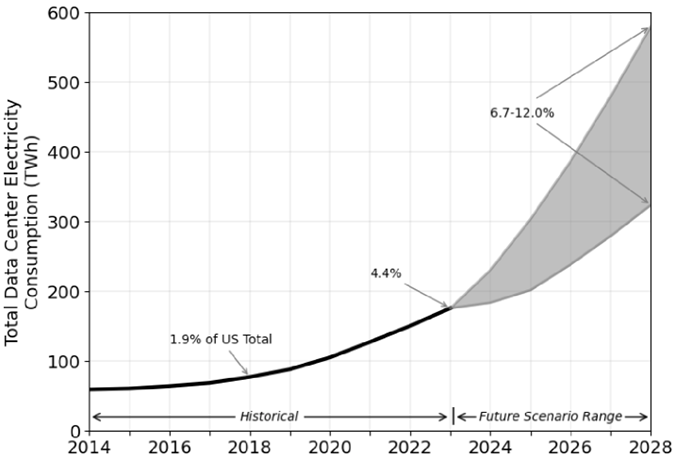
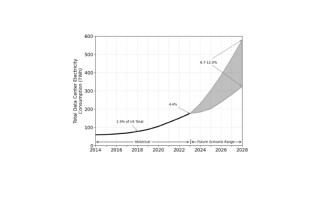
The use of electricity in U.S. data centers was steady from 2005 to 2017 with small annual increments. disrupted that stability starting in 2017 (Source: 2024 U.S. Data Center Energy Usage Report, Berkeley Lab).
This raises a natural question: Why does AI need so much energy? What is happening inside these machines that makes them so power hungry?
The Energy Toll of Learning: Why AI Training Consumes So Much Power
Imagine how a traditional computer handles a task. It follows a sequence of instructions step by step—like a cashier scanning items at a checkout line: one barcode, one beep, then the next. The workload is orderly, predictable, and relatively contained.
Training a modern AI model is nothing like that. Instead, picture trying to scan every single item in an entire supermarket at the same time—not once, but over and over again, thousands or even millions of times. Now imagine that the “supermarket” contains billions of data points—words, images, audio clips, video frames—and that each pass through this massive inventory requires trillions of mathematical calculations. That is what AI training looks like at scale.
Large AI models are built on deep neural networks with billions—or even trillions—of parameters. During training, the system repeatedly adjusts these parameters through a process called backpropagation, comparing predictions against correct answers and fine-tuning itself incrementally. Each adjustment requires vast numbers of matrix multiplications, which are computationally intense and must be executed in parallel across thousands of specialized processors.
And this process runs for months inside enormous data centers packed with high-performance AI accelerators. These chips draw megawatts of electricity continuously. Even more energy is required to cool the hardware as the dense concentration of processors generates tremendous heat.
Always On, Always Drawing Power: The Energy Reality of AI Inference
As energy-intensive as training is, it is not where the largest ongoing electricity demand comes from. Training is a concentrated surge, a massive burst of computation over weeks or months. Inference, by contrast, is continuous. It never really stops.
Inference is what happens after a model has been trained. Every time someone asks an AI system a question, the model performs inference, i.e., the act of generating a prediction or response from what it has already learned.
One query may require only a fraction of a second. On a global scale, those fractions add up. Multiply that single interaction by billions of queries per day. The demand becomes relentless.
Unlike training, which eventually finishes, inference operates on a permanent basis. AI systems sit inside data centers around the world, waiting for the next request. And the next one. They must respond instantly, which means the infrastructure powering them must always remain active and ready.
Industry analysts estimate that roughly 80–90% of AI-related computing today is devoted to inference rather than training. The result is a persistent, high baseline energy demand.
The Energy Breakdown: What Really Consumes Power in AI Systems
Surprisingly, the biggest energy consumer is not the actual mathematical thinking the AI does. The energy hog is simply moving data around. If a computer chip were a city, then the math would be the quiet conversations people have with each other, while the data movement would be the traffic on its highways, streets, and alleys. A conversation barely uses any energy. Traffic congestion, on the other hand, burns fuel. Inside an AI processor, the imbalance is just as dramatic: moving data takes thousands of times more energy than performing the calculations themselves.
Stanford professor Mark Horowitz quantified this years ago. He showed that doing a small calculation inside a chip uses about as much energy as flicking on a tiny LED for a minuscule instant. Sending data back and forth between the chip’s memory and the processors is like turning on an old incandescent streetlamp. The comparison is not even close. Now imagine doing that trillions of times. The cost adds up shockingly fast.
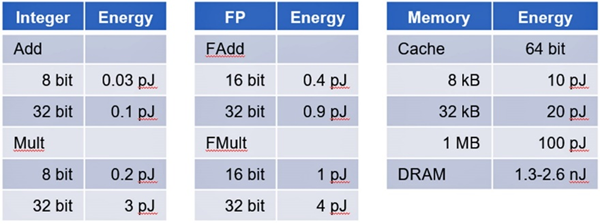
Energy dissipation across components varies widely from less than one picojoule for integer arithmetic in adders and multipliers to several picojoules for floating-point operations. Memory access proves even more costly: retrieving data from cache consumes 20 to 100 picojoules while accessing DRAM jumps by up to three orders of magnitude, surpassing 1,000 picojoules (Source: Stanford University).
Throughput Inefficiency: When AI Chips Wait Instead of Compute
While part of the energy imbalance in AI systems is rooted in semiconductor physics, the fact that moving data consumes more energy than performing arithmetic, another major factor is the uneven pace of technological progress.
Over the past three decades, processors have improved at a breathtaking rate. The number of transistors per chip has surged, parallelism has exploded, and specialized AI accelerators can now perform astonishing numbers of operations per second. Compute capability has grown exponentially.
Memory systems have not kept up. This growing disparity is known as the “memory wall.” Processor speeds have scaled dramatically, but memory bandwidth (how fast data can be delivered) and memory latency (how quickly it can be accessed) have improved far more slowly. The two curves are diverging. And that divergence sits at the heart of AI’s throughput inefficiency.
The Illusion of Peak Performance
On paper, a modern AI processor might advertise performance measured in the hundreds of teraflops or even petaflops. In theory, it can execute a quadrillion operations per second.
In practice, real-world performance often reaches only a fraction of that—sometimes less than 10–20% of peak capacity when running large AI models—because the processor spends much of its time waiting for data to arrive.
Imagine owning a sports car capable of 200 miles per hour—but being trapped in traffic congestion almost all the time. The engine is powerful. The design is sophisticated. But the road infrastructure can’t support that speed. In AI systems, the “traffic” is data movement.
Parameters must be fetched from memory. Activations must be written back. Intermediate results must be transferred across chip boundaries. Each of these steps consumes time and energy. When data cannot be delivered quickly enough, compute units stall, still burning power while doing no useful work. The unused computational potential does not vanish quietly; it becomes thermal overhead.
Architectural Mismatch
The root cause lies in compute architectures.
The permeating CPUs were designed for sequential, general-purpose tasks. They excel at control logic, branching, and diverse workloads, but not at feeding thousands of parallel arithmetic units simultaneously.
Conversely, the workhorse of AI processing GPUs was originally engineered for rendering images, where large amounts of data are processed in parallel. They are far better suited for AI workloads than CPUs, but even GPUs inherit memory hierarchies and data movement assumptions shaped by graphics applications, not neural networks.
Modern AI workloads are not simply “bigger.” They are structurally different.
Large neural networks require massive matrix multiplications, repeated reuse of model parameters, extremely high memory bandwidth, tight synchronization across parallel units, rapid movement of data between chips, and across racks. The appetite for data delivery has grown faster than the industry’s ability to supply it efficiently.
As a result, today’s AI accelerators resemble elite athletes with extraordinary muscle mass—but insufficient blood flow. Their computational engines are enormous, yet their circulatory systems, i.e., the pathways that move data between memory and compute, cannot keep pace.
Data Movement: The Hidden Energy Cost
In many AI workloads, moving data consumes more energy than performing the computation itself.
Fetching a value from off-chip memory can cost orders of magnitude more energy than multiplying two numbers. When scaled across billions or trillions of operations, this imbalance dominates overall power consumption. This is why throughput inefficiency is not just a performance problem, it is an energy problem.
Until memory systems, interconnects, and compute architectures evolve in tandem, AI processors will continue to operate far below their theoretical limits—consuming substantial electricity not just to compute, but to wait.
Conclusion: Rethinking AI Hardware for a Sustainable Future
Solving this problem will require far more than incremental refinement in existing computing architectures. The era when performance improvements could be achieved simply by adding more compute units is over. AI has exposed a deeper architectural constraint: computation is no longer the dominant cost. Data movement is.
Next-generation AI processors will not be defined by how many trillions of operations per second they can theoretically deliver. Instead, they will be judged by how efficiently they orchestrate the flow of data, how intelligently they minimize movement, localize memory access, and reduce idle cycles.
The semiconductor industry must begin designing chips around data flow, much like modern cities redesign infrastructure around traffic flow. Adding more lanes to a highway does not solve congestion if entry and exit points remain bottlenecks. Likewise, adding more arithmetic units does not solve AI’s efficiency problem if memory bandwidth and interconnect architecture remain constrained.
Today’s large AI systems often operate at roughly 10–20% of their advertised peak performance under real workloads. Raising that figure toward 80–90% would represent not just a performance breakthrough, but an energy revolution, dramatically reducing wasted power, lowering cooling requirements, and enabling sustainable scaling.
This shift requires architectural innovation, not just fabrication improvements. Computation is abundant. Data movement is expensive. The sooner hardware architects internalize that truth, the more sustainable and scalable the future of artificial intelligence will be.
Lauro Rizzatti is a business development executive with VSORA, a pioneering technology company offering silicon semiconductor solutions that redefine performance, and a noted chip design verification consultant and industry expert on hardware emulation.

Lauro Rizzatti is a business development executive with VSORA, a pioneering technology company offering silicon semiconductor solutions that redefine performance, and a noted chip design verification consultant and industry expert on hardware emulation.



