
The Perplexities of Predictive Maintenance: Generating and Leveraging Failure Data
April 16, 2019
Story

We?ll explore one of the most crucial, and frequently missed, components of predictive maintenance: workflow failures and knowing how to predict them.
While having an estimate of the time until failure is useful, even more valuable is information that describes the type of failure expected to occur (the root cause). Models that predict the type of failure can be trained on historical failure data, however, engineers commonly experience a lack of failure data for the various failure scenarios. For my third and final blog, we’ll explore one of the most crucial, and frequently missed, components of predictive maintenance: workflow failures and knowing how to predict them.
Here are two viable solutions that teams can leverage to stop this lack of failure data from becoming a fatal deficiency during predictive maintenance implementation:
- Generate sample failure data: Historically used tools such as failure mode effects analysis (FMEA) provide useful starting points for determining which failures to simulate. From here, engineers can incorporate behaviors into the model in a variety of scenarios, which simulate failures by adjusting temperatures, flow rates, or vibrations, or adding a sudden fault. When simulated, the scenarios result in failure data that can be labeled and stored for further analysis.
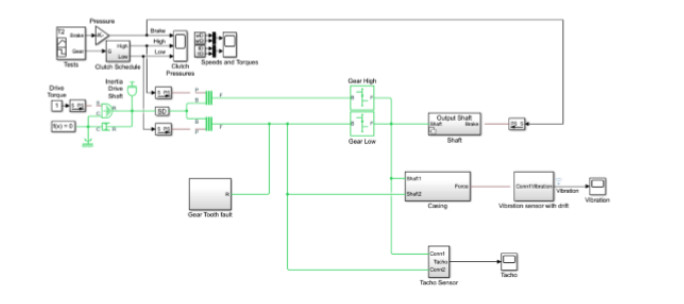
- Understand the data available: Depending on what sensors are available, certain types of failures may require looking at several sensors simultaneously to identify undesirable behavior. But looking at the raw data from dozens or hundreds of sensors can be intimidating. In this case, unsupervised learning techniques (a branch of machine learning) such as principal component analysis (PCA) transform raw sensor data into a lower-dimensional representation. This data can be visualized and analyzed much more easily than high-dimensional raw data, enabling you to find valuable patterns and trends in unlabeled data. Even if failure data is not present, operations data might indicate trends about how a machine degrades over time and estimate remaining useful life (RUL) for components.
Simple Steps to Reducing Learning Curves
Another common obstacle engineers face involves the modeling and testing of algorithms that may seem foreign and intimidating.
Engineers looking to reduce this learning curve can follow these three simple steps:
- Define goals: Define upfront what your goals are (e.g., earlier identification of failures, longer cycles, decreased downtime), and how the predictive maintenance algorithm will affect them. As an early step, build a framework that can test an algorithm and estimate its performance relative to your goals to enable faster design iterations. This will ensure that all different approaches are compared on a level playing field.
- Start small: Practice using a project with a deeply understood system, the simpler the better. For example, start by looking at things at the component level rather than the system or subsystem level. This will reduce the number of faults that need to be investigated and shorten the time to develop an initial prototype.

- Gain confidence: When you start seeing promising results, use the domain knowledge within your team to predict different outcomes based on their cost and severity. Run a predictive maintenance model in the background of existing maintenance procedures, to understand how the model works in practice.
In summary, define clear goals, start small, validate against data, and iterate until confident with the results.
To read about other obstacles discussed in this blog series, visit the past two blogs:



