Clocking Python Code the Clever Way
July 11, 2022
Story
Since the Fibonacci sequence generator was implemented in Python, some of the top questions on StackOverflow have to do with the most efficient and “Pythonic” implementation of a particular algorithm. In this article, we’ll look at a popular operation: reversing a list.
In a previous blog post we leveraged Percepio’s Tracealyzer to gain insight in the performance of two different implementations of the same algorithm. Specifically, we determined that it was more performant to implement an algorithm to generate the Fibonacci sequence using an iterative function rather than a recursive function. We didn’t need to generate a substantial number of entries in the sequence and measure time to identify the performance difference; instead, we were able to use Tracealyzer to give us deep insight into the performance of the implementations while generating only ten entries in the sequence.
Since the Fibonacci sequence generator was implemented in Python, let’s expand on this further. Some of the top questions on StackOverflow have to do with the most efficient and “Pythonic” implementation of a particular algorithm. In this article, we’ll look at a popular operation: reversing a list.
According to the following question on StackOverflow, there is some debate about the performance of one implementation over another when reversing a list. To gain insight ourselves as to the difference, we can implement both techniques in a simple application as shown in the listing below; we also include the necessary source code to capture the markers required for Tracealyzer to evaluate the performance of each implementation:
import lttngust
import logging
def example():
list_basis = list(range(10))
logging.basicConfig()
logger = logging.getLogger('my-logger')
logger.info('Start')
reverse_list = reversed(list_basis)
logger.info('Stop')
logger.info('Start')
reverse_list = list_basis[::-1]
logger.info('Stop')
if __name__ == '__main__':
example()
We’ve created a list of 10 elements and used the built-in “reversed” function along with a technique called “slicing” in Python to reverse the list. Slicing simply takes certain elements of a list and returns them to a new list; in our case, we’re slicing the entire list but traversing backwards.
As in the previous blog post, we can create an LTTng session, run our Python script, open the resulting trace in Tracealyzer, and evaluate the results:

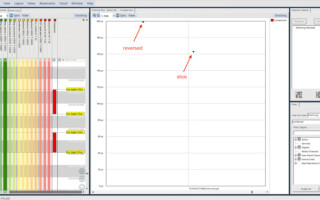
We can see that the implementation using the reversed function takes approximately 475 microseconds and the implementation that uses slicing takes approximately 360 microseconds.
Let’s see what happens when we increase the number of elements in the initial list by 10x, resulting in a list consisting of 100 elements:
import lttngust
import logging
def example():
list_basis = list(range(100))
logging.basicConfig()
logger = logging.getLogger('my-logger')
logger.info('Start')
reverse_list = reversed(list_basis)
logger.info('Stop')
logger.info('Start')
reverse_list = list_basis[::-1]
logger.info('Stop')
if __name__ == '__main__':
example()
Again, we re-run the necessary steps to create an LTTng session, run our application, and open the resulting traces in Tracealyzer, which shows us the following graph:

Although we see the same pattern as before, where the slicing technique performs better than the reversed function, we can see that the absolute time of both mechanisms has nearly halved when compared to the results with only 10 elements. This is interesting, since we expected that the amount of time taken for both techniques should be less in the case of 10 elements when compared to the case of 100 elements. Let’s collect more data by first updating the Python script to allow us to collect more data in an automated fashion:
import lttngust
import logging
import sys
def example(list_size):
list_basis = list(range(list_size))
logging.basicConfig()
logger = logging.getLogger("my-logger")
logger.info("Start")
reverse_list = reversed(list_basis)
logger.info("Stop")
logger.info("Start")
reverse_list = list_basis[::-1]
logger.info("Stop")
if __name__ == '__main__':
example(int(sys.argv[-1]))
In the example above, we’re simply allowing ourselves to pass in the number of elements we want in the list. We can then create the following bash script, which will allow us to execute the Python application, giving it an argument of 10 and 100 in successive fashion, collect the time it took to reverse the list using both the reversed function and the slice method, and store that data; the script will cycle through each test 10 times.
#!/bin/bash
set -e
list_compare() {
echo "Running test with a list size of $1 elements"
lttng create
lttng enable-event --kernel sched_switch
lttng enable-event --python my-logger
lttng start
python3 list_compare.py $1
lttng stop
lttng destroy
}
for i in {1..10}
do
list_compare 10
cp -r ~/lttng-traces/auto* "/home/pi/percepio/elements_10_trace_$i"
chown -R pi: "/home/pi/percepio/elements_10_trace_$i"
mv ~/lttng-traces/auto* ~/lttng-traces/archive/
list_compare 100
cp -r ~/lttng-traces/auto* "/home/pi/percepio/elements_100_trace_$i"
chown -R pi: "/home/pi/percepio/elements_100_trace_$i"
mv ~/lttng-traces/auto* ~/lttng-traces/archive/
done
When we open the resulting traces in Tracealyzer and chart them, we see the following trends:

The yellow and orange plots represent the reversal times for 10 element lists, and the green and dark red plots represent the same for 100 element lists. We can see a few instances where the execution times for the reversal of 10 element lists was in line with the execution times for 100 element results. Similarly, we can see that there was one instance where the execution time of reversing a 100 element list was reduced and along the lines of the execution time of reversing a 10 element list. However, overall, we can see that the execution time of reversing a 10 element list is roughly half the time needed to reverse a 100 element list.
Perhaps we observed one of these anomalies in the previous case? Let’s analyze the results with 1000 elements:

Again, we see the same pattern where using the slicing technique takes less time when compared to using the reversed function. However, even though we increased the number of elements in our list again by 10x (to a whopping 1000 elements), the time for each implementation is roughly the same as it was for 100 elements, and still half as much time when compared to only 10 elements.
Let’s increase the list size to 100k elements and observe the results:

Whereas previously we observed that the slice technique took about half as much time as the reversed function, here we can see the opposite. As a matter of fact, with a list size of 100k elements, the slice technique took about 15x longer!
In summary, we have gained some valuable insight from this simple exercise. First, it appears that the slice technique takes less time, compared to the reversed function, for a list size of “a few” elements (up to 1000). However, when we increase the list size to 100k elements, we can see that the slice technique takes approximately 15x longer than the reversed function. Second, when we ran multiple iterations of smaller sized lists, we did notice instances where the time to reverse a list of 100 elements was approximately the same as the time to reverse a list of 10 elements; however, the overall trend was that reversing a list of 10 elements took less time than reversing a list of 100 elements, which is expected! We can analyze the trace captured by Tracealyzer in more detail to understand the cause of the observed anomalies.
The key takeaway here is that Percepio’s Tracealyzer allowed us to perform this detailed analysis without much instrumentation infrastructure; we were able to discern performance numbers that are in the order of 100s of microseconds!
As Python has been the popular language for machine learning, it is vital that we have a tool that can quickly allow us to compare the performance of one algorithm to another. We can develop small functions that isolate the algorithm we are looking to evaluate and use Tracealyzer to provide us with the necessary insight about the performance of the algorithm across different dimensions. Tracealyzer can also quickly uncover anomalous behavior that might require further analysis.
Mohammed Billoo is Founder of MAB Labs Embedded Solutions. He has over 15 years of experience architecting, designing, implementing, and testing embedded software, with a core focus on embedded Linux. This includes custom board bring-up, writing custom device drivers, and writing application code. Mohammed also contributes to the Linux kernel and is an active participant in numerous open-source efforts.
He is also an Adjunct Professor of Electrical Engineering at The Cooper Union for the Advancement of Science and Art, where he teaches courses in Digital Logic Design, Computer Architecture, and Advanced Computer Architecture. Mohammed received both his Bachelor's and Master's of Electrical Engineering from the same institution.

MAB Labs founder, Mohammed Billoo, is an embedded software consultant with over 12 years of experience in embedded software across a multitude of domains, including Defense, Space, and Commercial. He is an avid blogger and contributor to the open-source community. Mohammed is also an Adjunct Professor of Electrical Engineering at The Cooper Union.