
SequenceL for C++ programmers saves time and angst
August 20, 2014

If you design the software right, you can really take advantage of multicore systems. As the April 2013 Dr. Dobbs article "The Quiet Revolution in Pro...
If you design the software right, you can really take advantage of multicore systems.
As the April 2013 Dr. Dobbs article “The Quiet Revolution in Programming” pointed out, a major shift has occurred in software development in just the last few years. The ubiquity of mobile apps, the enormous rise of HTML and JavaScript front-ends, and the advent of big data require programming in multiple languages. As the article highlighted, we have had to become polyglots to develop almost any current application. It’s the classic hammer and nail problem – choosing the appropriate tool for the job.
The same is true when developing applications for today’s multicore, many-core, and now heterogeneous systems. C++ is one of the most popular programming languages in use today. Since its inception at Bell Labs in 1979, it’s been implemented on a wide variety of hardware and operating system platforms and proven to be an efficient, performance-driven programming language. Yet it was developed decades before multicore and many-core systems began to proliferate in 2004.
Due to its popularity and performance, there have been various attempts to extend C++ to multicore systems with parallel directives, compiler hints, and so on. This was fine for early dual-core systems, where simple partitioning was sufficient. Many programmers were even able to use it for quad core systems. However, these band-aid approaches haven’t addressed the root of the parallel programming problem to allow scaling to hundreds or thousands of cores. This is because these manual approaches leave the hard work of identifying and implementing race-free parallelisms to the programmer.
SequenceL is an appropriate tool for the multicore and many-core programming job, working in concert with C++ (and optionally OpenCL). It retains and leverages key strengths of C++, including programmer familiarity, wide platform support, and available frameworks and tools. It also relies on C++ for I/O since its inventors saw no need to reinvent that. In fact, many users simply think of it as an easy-to-use front-end/pre-processor to C++. In the case of systems with GPUs, the automatic OpenCL generation also averts the need to learn and incorporate low-level CUDA or OpenCL code and associated scaffolding.
SequenceL is a simple yet powerful functional programming language and auto-parallelizing tool chain that quickly and easily converts functional specifications to robust, massively parallel C++ code. It’s a Turing complete, domain-independent language that was originally developed in partnership with NASA for applications in guidance, navigation, and control systems. Its semantics are based solely on two computational laws that are race-free, Consume-Simplify-Produce (CSP), and Normalize-Transpose (NT). These semantic operations expose all parallelisms in a program, even fine-grain parallelisms programmers may never see, and avert the need to specify parallelisms or implementation structures in the code.
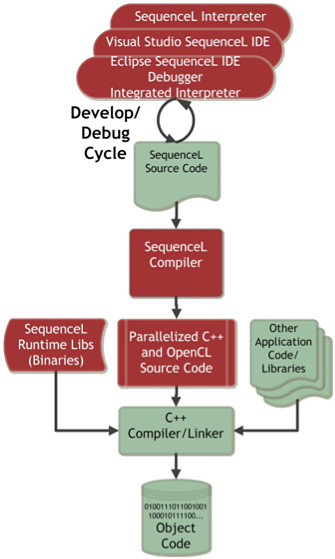
SequenceL is especially useful for scientists and engineers who have to implement difficult algorithms because its function definitions take the form of equations. In SequenceL, equations often resemble a transliteration, rather than an implementation, of the functional design (technically speaking, one might say that SequenceL is a tool for not writing algorithms). Other functional languages, such as Haskell and OCaml, also share this property.
What distinguishes SequenceL within this family is a combination of two things. First, the core language reference for SequenceL is just 22 pages, so it can be learned in its entirety in a matter of hours Second, SequenceL’s unique NT semantic operation, described below, eliminates the need for most instances of recursion and iteration, and enables the compiler to automatically detect and implement parallelisms available in the design for high performance on multicore and many-core systems.
We’ll show an example here. The textbook definition for vector dot product for two vectors u and v is defined as:

In English, the definition above reads, the dot product of vectors u and v is the sum of the products of their respective members. The vector dot product is not built into SequenceL, but it can simply be written as follows:
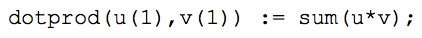
The parenthesized integer after each argument indicates its dimension, with 1 being a sequence of scalars, and 2 being a sequence of sequences of scalars (i.e., 2D matrix), etc.
Building on that, the textbook definition of Matrix Multiply is: the product of an m×p matrix A with a p×n matrix B is an m×n matrix denoted AB whose entries are given by:

This function can be implemented in SequenceL as follows:

The subscript [i,j] following the lefthand side is a shorthand used when it’s more convenient to define the elements of a data structure pointwise, and the subscript ranges can usually be inferred from context by the SequenceL compiler. In cases where the range can’t be inferred, or the inferred range would be overly broad, the programmer can restrict it explicitly. The inferred range is never too narrow, since it is, by default, the range of all subscripts for which the righthand side is defined.
In this definition, the let…in construct says that k will be the sequence [1,...,size(B)] in the expression that follows it. In this context, the expression sum(A[i,k]*B[k,j]) is interpreted to mean the sequences whose respective members are A[i,k]*B[k,j], as k ranges from 1 to size(B). As in dot product, the “respective” qualifier is implicit, and is inferred from the operators and arguments used. The sum operator gives the sum of this sequence, which is the desired result.
There are three things to notice about the definitions above. First, they’re fairly short and circumvent the need for explicit iteration or recursion. Second, though it’s not apparent from just two examples, the constructs that take the place of iteration here turn out to be quite general in purpose, and aren’t limited to matrix/vector arithmetic, or even to numerical methods. Third, those same constructs also trigger the compiler to auto-parallelize the code on any number of processors in a multicore or many-core system (including GPU). Parallel matrix multiplication is implemented in SequenceL using the same three lines of code as the sequential (single-thread) definition. Contrast that with its C/MPI equivalent, which is more complex (over 90 lines), making it easier to inject coding errors and more difficult to QA.
Basic how-to
To start, let’s look at a function to compute factorials, which is sometimes viewed as the “Hello World” of functional programming. In SequenceL it’s as follows:
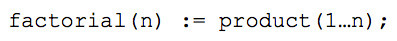
In English, this says the factorial of n is defined to be the product of a list of consecutive integers, starting with 1 and ending with n. We could also write it using recursion:

which is also nice and short but, as most people know, runs inefficiently in terms of both time and memory. What not everyone knows is that there’s an alternative recursive implementation:

that runs as light and fast as the standard iterative implementation, and indeed compiles to the same machine code so long as optimizations are turned on. This optimization, called tail or last-call recursion, is available in most compiled languages. The general form of the tail-recursive idiom is:

which equals the following loop in procedural pseudocode:

For example, taking the Fibonacci numbers to be 1, 1, 2, 3, 5, 8, 13…, a function to compute the nth Fibonacci number, (i.e., the nth number in the sequence), might procedurally look like:

and, as a tail recursive loop in SequenceL, look like:

The tail recursive idiom used above is stock in trade for programmers in any functional language. It requires about the same number of keystrokes as the procedural code, but it can be cumbersome to use especially where a simple for-loop would do. Fortunately, it’s not necessary as often as you might expect, due to constructs described later.
Normalize-Transpose
Many instances of looping and recursion can be avoided altogether in SequenceL using a distinctive semantic operation known as Normalize-Transpose, or simply NT. The NT operation kicks in automatically when a function is called with arguments whose dimension is deeper than its signature indicates. Arguments with this property are said to be overtyped. For example, the second argument in the expression:
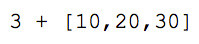
is overtyped because the floating-point addition operator (+) expects two scalars as arguments:

Click to enlarge
The first step in handling NT is the duplication of all non-overtyped arguments and operations, as many times as necessary to match the length of the longest overtyped argument:
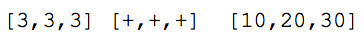
This step is known as normalization. Next, a transpose is performed, gathering respective members of the normalized expression together as members of a sequence. In this case we obtain:

This semantic applies any time one or more arguments of an expression are overtyped, and when all overtyped arguments are lists of the same length. For example, we have:

The operation applies to more deeply nested lists as well. For example, we have the following, where, as above, the operator or operators being worked on by NT in each step occur in boldface:

The NT operation performs pointwise addition of vectors and matrices, for example, as expected. After working through a few examples and internalizing the principle that less deeply nested arguments get duplicated, the effects of NT become easily predictable and flexibly useful. We can write, for example:

which avoids the usually required deployment of iteration/recursion through an NT over the possible nontrivial divisors of n (the quantifier none simply checks to see if true is a member of a list). Matrix addition is rendered trivial by NT. The vector dot product is not rendered trivial (not being a purely pointwise operation), but it is rendered almost trivial and, as you may recall, can be written as:

Now that NT has been explained, the function’s operation can be clarified as promised. As expected, the call dotprod([1,2,3],[4,5,6]) would result in the following evaluation:

NT can also create a filtered list, that is, a list containing only those elements satisfying a given property. To do this, note that in SequenceL the expression x when p has value x if p is true, and is empty otherwise. Moreover, the list [1,2,empty,3] is equal to the list [1,2,3]. Thus, we can use when clauses together with NT to create a filtered list, as in:

Given these definitions, together with the definition of Prime, the call primesIn([1...10]) would return the list [2,3,5,7], containing all primes in the original argument list.
Automatic parallelism
Since NT is triggered when the same operation is being calculated independently on each member of a data structure, or on respective corresponding members of different data structures, the sequence of operations that results from an NT can, in principle, be done in parallel. The SequenceL compiler takes this as a signal that the operations can be parallelized, and the intelligent runtime environment implements the parallelisms depending on the number of cores available and the tradeoff between parallel speedup and communication overhead, as well as load balancing and other considerations.
We’ve found that the programmer needn’t think about this feature of the language at all and can just focus on the problem to be solved. The thought process of designing a SequenceL program is the same whether the intended platform is single- or multicore. But that process elucidates potential parallelisms automatically because the parallelisms tend to occur precisely in places where the use of NT makes the programming easier.
Second, the performance of the parallel executables is quite strong, often nearly as good as code that’s been painstakingly hand-parallelized by experts, yet in a fraction of the time. Cost and time-to-market comparisons between SequenceL and by-hand parallelization, in cases where the development has been done both ways, come in at 10 to 1, estimating conservatively. This time-to-market advantage is even larger now that the SequenceL compiler has the option to also output OpenCL to target a GPU, a very tedious process to manually code. The automatic OpenCL generation also averts the need to learn and incorporate low-level CUDA or OpenCL code and associated scaffolding.
A larger example
The example here is taken from a commercial program in SequenceL, written under contract with Emerson Process Management. The overall program is a graph routing algorithm, as part of the WirelessHART communication standard (IEC 62591). To work in largescale, noisy, industrial applications with thousands of nodes, it requires both reliability and parallel performance.
The top level functions in this example give the list of nodes in a graph G that have exactly a given number n of parents in a given set of nodes S. For comparison, first look at the algorithm in C++:

Click to enlarge
Now, here’s the SequenceL implementation:

Click to enlarge
Now, if X is a list of nodes of graph G, kParents(X,Ns,G,k) will be the sublist of X containing only those nodes with exactly k parents among the members of Ns.
The goal of the SequenceL implementation on this project was to improve performance through automatic parallelization. Prior to implementing in SequenceL, the customer’s Java implementation was taking more than five minutes for 50 nodes, and scaled cubically, so 200 nodes is about 64x as complex as 50 nodes. With current software technology, that’s 5 hours and 20 minutes; a 1,000-node refinery would take a solid month to process. The goal was to generate those graphs for a 200-node network in less than one minute.
Working from the original project’s whitepaper, the entire application was written in about 200 lines of SequenceL code in one week, compared to five or more months it takes using Java. Further, the SequenceL code was more robust; it was correct the first time and was used to fix problems in the Java version, since SequenceL was essentially a transliteration of the spec verses a software engineering undertaking.
As for meeting the performance goal, the SequenceL implementation easily beat the target performance goal in both time and scalability. It generated the downlink graph in 4.5 seconds and the entire graph set in 13.4 seconds on one core (and 9.3 seconds on two cores). Thus, the SequenceL development was more robust, was completed in far fewer programmer hours, and enjoyed better runtime performance, including parallel speedups.
In addition, SequenceL was designed from the beginning to use two languages in concert. By outputting massively parallel C++ (and optionally OpenCL), SequenceL can work with most any language, allowing different portions of the program to be written with the tool which fits best. Since most projects involve enhancing existing programs, the developer can simply refactor just a portion of their code in SequenceL and then re-insert the parallelized C++ output back into their existing program.




