Classic DSP, New Neural Networks & Better Benchmarks Improve Local Voice Activation at the Edge
July 19, 2021
Story

If you’ve ever used a virtual assistant, you likely assumed you were talking to a device so smart it could answer almost any question you asked it. Well, actually, Amazon Echos, Google Homes, and other devices like them usually have no idea what you’re talking about.
Yes, these devices leverage AI. But not in the way you’d expect. More often than not the endpoint hardware simply detects a wake word or trigger phrase and opens a connection to the cloud where natural language processing engines analyze the request. And in many cases they don’t just transmit a recording of your question.
“What it started off with we would call a ‘weak wake word’ at the edge,” says Vikram Shrivastava, Senior Director of IoT Marketing at Knowles Intelligent Audio in Palo Alto, California. “You would still have to send the entire recording up to the cloud to get a real solid second that someone actually said, ‘Okay, Google’ or someone actually said the trigger word in question.
“This would generate something that we call the true positive rate (TPR) of detection and false accepts,” he went on. “So if you didn't say Alexa but it sent a message to the cloud anyway, then the cloud would say, ‘No, you didn't. I double checked and you're wrong.’ And that was because the edge devices were not sophisticated enough in their edge detection algorithms.”
In other words, many virtual assistants go to the cloud at least twice: Once to verify that they are being addressed and a second time to respond to the request.
Not so smart, huh?
Conversations at the Edge
There are several drawbacks to this architecture. Sending requests to the cloud adds time and cost, and also opens potentially sensitive data to security and privacy threats. But the most limiting factor of this approach is that opening and maintaining these network connections gobbles up energy, which prevents voice AI from being deployed in entire classes of battery-powered products.
Herein lies the challenge. Many edge devices use power-efficient technologies that don’t equip the performance to run AI locally, and therefore must send voice commands to the cloud, which incurs the penalties mentioned previously. In an effort to escape this cycle, audio engineers at Knowles and elsewhere are integrating the traditional efficiency of digital signal processors (DSPs) with emerging neural network algorithms to increase intelligence at the edge.
“What we are seeing now is that the edge devices are beginning to transition to the built-in ecosystem,” Shrivastava explains. “So now you can have up to 10, 20, 30 commands, which can be all executed at the edge itself.
“Some of the trigger word improvements have significantly improved the TPR at the edge,” he continues. “Where audio DSPs actually played a big role and audio algorithms at the edge play a big role is just the performance of detecting these trigger words in noisy environments. So if my vacuum cleaner running and I'm trying to command something, or you’re in the kitchen and the exhaust fan is running and you're trying to talk to your Alexa unit.
“This is what we call a low SNR, which means the noise in the environment you're in is very high, and average talking would be lower than the average noise.”
Knowles is a fabless semiconductor company known for its high-end microphones, and more recently for audio processing solutions. The latter began with Knowles’ 2015 acquisition of Audience Inc., a company founded on academic research in computational auditory scene analysis (CASA), which studies how humans group and distinguish sounds that are mixed with other frequencies. That research led to specialized audio processors capable of extracting one clear voice signal from background noise in the way Shrivastava described.
In addition to those audio processors, products like the Knowles AISonic Audio Edge Processors integrate DSP IP cores from Cadence Design Systems. Cadence’s Tensilica HiFi portfolio of audio DSPs has gained popularity in intelligent edge voice applications thanks to its energy efficiency and ability to efficiently digital front-end and neural network processing capabilities.

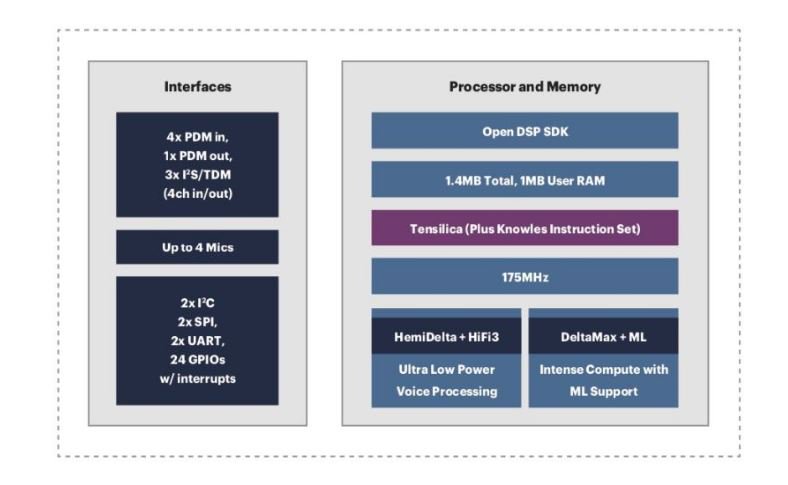
Figure 1. Knowles integrates Cadence Tensilica HiFi DSP cores into its AISonic Audio Edge Processors. (Source: Knowles Intelligent Audio).
Knowles deploys these Tensilica-based audio processing solutions into everything from single-microphone AISonic SmartMics to high-end devices like high-end Honeywell or Nest-class thermostats where they manage anywhere from three to seven microphones.
“The microphones are digital, the DSP is digital, the communication between the DSP and the host processor is also digital,” Shrivastava says. “Let’s just say it’s an Ecobee device. There’s an Arm-based host processor in there that s running a little Alexa stack, which will take the command phrase from the Knowles subsystem.
“We can take that core microphone data coming in, we can do beamforming, we can find out which direction you're talking in, we can improve and amplify a signal only from that direction, ignore the noise from the other direction, do some other noise suppression as well, and then detect the trigger word accurately,” he continues. “In a well-tuned system, we would have less than three false detections in 24 hours. And we can do that all within a 1 MB of memory.
“And the value proposition behind having all of that in there is, just to give you an idea, if you needed an Arm core running at 1 GHz to do speech processing, we would be running the same process at about 50 MHz on our DSP, so almost a factor of 20,” the Knowles engineer explains. “And that directly translates into power consumption.”
Obviously, Tensilica cores don’t provide the level of efficiency Shrivastava is describing out of the box. Application engineers must tune the system for the end use case. For Cadence Tensilica customers, this process is simplified by the availability of custom instructions.
“One of the things that'’s unique about Tensilica is the ability to use Tensilica Instruction Extensions, or a TIE,” says Adam Abed, Director of Product Marketing at Cadence and a former Knowles employee. “Knowles uses that extensively to customize and build very efficient floating-point processing.
“And so together, we’ve built this really nice, unique product that’s able to not only deliver high-quality audio from the MEMS and microphone standpoint, but also do some things like cleanup or voice trigger in a super low power manner without waking up most of the system,” he adds (Figure 2).
Figure 2. Cadence's Tensilica HiFi family of DSPs provides the performance scalabity and instrucion customization to meet the requirements of a range of intelligent voice processing systems. (Source: Cadence Design Systems)
To maximize both power efficiency and AI performance, the wake-up process Abed mentioned is usually implemented in phases depending on the system. As his colleague Yipeng Liu, Director of Product Engineering at Cadence, explains, IP like the HiFi 5 this requires “a combination of traditional DSP plus the ability to process the neural network itself.
“The first layer is to detect if there's actually any voice, so that's a very lightweight voice activity detection,” Liu says. “If it detects voice, then you wake up the next layer of processing called keyword spotting. That can be pretty lightweight processing. It just says, ‘I heard a word that sounds like what I'm listening for.’”
“Then there is a third layer, which is once you detected a trigger word, you may want to wake up another layer of processing that validates, ‘Yes, I did hear what I think I heard.’ That's actually a very heavy processing load,” she continues “From there you continue to listen and that becomes a heavy-load neural network processing.
“It could take 1 MHz, it could take 50 MHz. It really depends.”
Picking the Best Voice AI Stack: “It Depends”
And when it comes to AI and ML technology evaluation, it really depends.
Of course, determining how many megahertz, how much power consumption, keyword detection accuracy, and other key performance indicators of an intelligent audio system vary from design to design. Liu went on to explain that this variety makes it difficult to gauge the viability of smart voice system components, even DSPs, because metrics like tera operations per second (TOPS) don’t “actually matter” when dealing with highly specialized DSPs.
“You can do 1,000 TOPS, but all the operations are the wrong type. But you may only need 200 MHz for your certain type of processing. Or if you write the instructions and one device takes 50 MHz instead of 200 MHz, even though they have the same number of tops, essentially you have more effective tops,” she adds.
Recently, though, MLCommons has looked to simplify the process of evaluating edge AI components by teaming with EEMBC on a new system-level benchmark: MLPerf Tiny Inference. As the latest in a series of training and inferencing benchmarks from ML Commons that span from cloud to edge, MLPerf Tiny Inference currently provides a standard framework and reference implementation for four use cases: keyword spotting, visual wake words, image classification, and anomaly detection.
The MLPerf Tiny workloads are designed around a pre-trained 32-bit floating-point reference model (FP32), which Colby Banbury, PhD student in the Edge Computing Lab at Harvard University and MLPerf Tiny Inference Working Group co-chair, identifies as the current “gold standard for accuracy.” However, MLPerf Tiny Inference offers a quantized 8-bit integer model (INT-8) as well.
What sets MLPerf Tiny apart as a system-level benchmark is its flexibility, which helps avoid single-point performance assessments of compute performance, for example, by allowing organizations to submit any component within an ML stack. This includes compilers, frameworks, or anything else.
But being too flexible can be a negative when it comes to benchmarks, as you can very quickly end up with multiple vectors that aren’t related. MLPerf Tiny addresses this through two different divisions – open and closed – which provide submitters and users with the ability to measure ML technologies for a specific purpose or against each other.
“MLPerf in general has this large set of rules. And it came out of this constant pulling factor in benchmarks between flexibility and comparability,” says Banbury. “The closed benchmark is something that's much more comparable. You take a pre-trained model and then you’re allowed to implement it onto your hardware in a manner that is equivalent to the reference model based on some specific rules that have been outlined. And so that’s really a one-to-one comparison of hardware platforms."
“But the landscape of Tiny ML requires so much efficiency, so many software vendors and even hardware vendors provide value at all different points in the stack,” the MLPerf Tiny co-chair continues. “And so for people to be able to show that they have a better model design, or that they might be able to provide better data augmentation at the training phase, or even different types of quantization, the open division allows you to essentially just solve it in whatever manner you want. We measure accuracy, latency, and optionally energy, and so you’re allowed to hit whatever optimization point your product is intended for.”
In short, the closed division lets users evaluate ML components on specific characteristics, while the open division can be used to measure a portion or the entirety of your solution. In the open division, models, training scripts, datasets, and other parts of the reference implementation can be modified to fit the submission requirements.
Hearing Clearly with Classic Signal Processing
But back to voice. The ultimate goal of audio AI is the ability to perform full-blown natural language processing (NLP) completely at the edge. Of course, this requires a lot more processing capability, a lot more memory, a lot more power, and a lot more cost than the market is ready for today.
“I would say we're still maybe two years away from true natural language at the edge,” says Knowles’ Shrivastava. “Where we are seeing success right now is in low-power, battery-based devices that want to add a voice and speech processing. So having some of these local commands or the built-in capability.
"It’s early days because you need a lot of resources for natural language understanding at the edge and this is still the domain of the cloud,” he continues. “In the last five years, we still haven’t seen a lot of natural language come to the edge. But definitely we are getting subset of context-specific commands moving towards the edge. And I think we will see more and more of that as they fit in some of the embedded processes.”
AI processing engines are being developed that promise to execute voice activation, recognition, and keyword spotting more efficiently, and enable more advanced, natural language-based workloads at the edge. In fact, Knowles and Cadence are both actively developing such solutions.
But in the short- to mid-term, there is still a need to make local decisions like voice trigger validation in real-time while consuming less power. So with their legacy of efficient floating-point processing on streaming data, why not try traditional DSP for novel new applications?
And if you’re not sure, there’s a benchmark for that.

Tiera Oliver is the assistant managing editor at Embedded Computing Design. She is responsible for web content editing, product news, and story development. She also manages, edits, and develops content for ECD podcasts, including Embedded Insiders.
She utilizes her expertise in journalism and content management to oversee editorial content, coordinate with editors, and ensure high-quality output across web, print, and multimedia platforms. She manages diverse projects, assists in the production of digital magazines, and hosts company podcasts by conducting in-depth interviews with industry leaders to deliver engaging and insightful discussions.
Tiera attended Northern Arizona University, where she received her bachelor's in journalism and political science. She was also a news reporter for the student-led newspaper, The Lumberjack.