
Code cleaning with SPARK and Ada: Cut development costs upfront
August 16, 2017

Leveraging an expressive and formal specification from the start makes it easier to respect requirements, provide automatic verification, and prevent problems or detect them early in development.
How fast can you get software out and ready?
For a long time, this single question has driven most of the embedded industrial industry. Getting this yearly release on time, meeting that functional milestone. And as long as software functions were relatively simple or secondary to system functionality, this was fine.
But with the increasing complexity and interconnectivity of systems, small failures or “glitches” that were once benign are now cause threats, sometimes even endangering human lives. Drones, self-driving cars, and medical devices are three very significant representations of this trend. The question then becomes not so much whether software can be delivered on time, but whether or not correct, safe, and secure software can be delivered in time. This is a whole different beast.
There is not a whole lot that can be done to deliver correct software outside verifying that it’s doing what it’s supposed to do. Unfortunately, traditional software development methodologies are not designed to ease formal specification, or to optimize verification costs. And the later a problem is detected, the more expensive it is to fix, to the extent that what can takes minutes to fix on day one could last months during integration. Yes, it’s possible to write extremely robust software with traditional languages and environments, but at a ridiculously high cost.
For embedded applications running on microcontrollers (MCUs), in particular, one element that adds even more complexity is the difficulty of writing tests. It may be impractical to write or even run extensive test campaigns when they involve low-level embedded functionality. Anything that can help clear out issues or ensure correctness before these procedures represents a huge cost savings.
Leveraging an expressive and formal specification from the start, on the other hand, makes it easier for the implementer to respect requirements, provide automatic verification, and thus either prevent problems or detect them very early in the development cycle.
The Ada and SPARK languages provide a unique solution in this regard, integrating specification, coding, and verification into a common formalism. The core principle of these languages is to specify as much as possible at the software level so that as many components as possible can be verified at the time of implementation.
The following examines a practical Ada or SPARK implementation, step by step.
Specification
One thing that stands out when comparing the Ada and SPARK languages to alternatives is the amount of information that can be added to software source code to capture constraints and intent in addition to actual functionality. A data type is not just a mere integer or float: it’s a semantic entity that can be associated with a set of valid values, a set of operations, minimal precision, memory representation, and even physical dimensions. Likewise, a function is not just a means of computing a value from parameters: it has a set of conditions under which it can be called, provides a set of guarantees when it returns, and has an impact on its environment (parameters and global variables).
There are many features of Ada and SPARK that can be used to enrich specification, but for the purposes of this article, let’s select one example:

This simple procedure reveals a lot in terms of its properties and behavior:
- First, C is an in out parameter, so it has to be initialized prior to being called and its value is modified in the subprogram. Note that there’s no indication whether it’s passed by copy or reference, which is automatically decided by the compiler based on language constraints and efficiency.
- E is an in parameter, or an input value not intended to be modified. A precondition requires that the container is not full prior to call. This is an extremely significant shift in terms of design, as in other languages a Push procedure may have been responsible for detecting the wrong calling context (if the container is full) and implementing mitigation techniques (or defensive code). Using a precondition, on the other hand, the procedure can safely assume that the container is not full (otherwise it would have been detected statically or dynamically, but more on that later) and avoid this extra code. The responsibility of validating input is implicitly placed on the caller, which can then raise it to its own callers until reaching a place in the code where data validation is indeed meaningful.
- The post-condition provides key properties on the behavior of the procedure – here, the fact that E is contained in the modified container and that the count is incremented.
Looking at some of the constraints associated with embedded development, another useful aspect is to specify memory mapping constraints. Ada allows declarative notation to specify how data structures are laid out in memory and at which addresses, allowing error-prone bitwise operations and consistency checks to be avoided. For example:

The above declares a data structure together with some fields associated with boundaries:
- The size of the data is fixed at 16 bits, and the next two aspects (with valued High_Order_First) essentially tell the compiler to use a big endian representation.
- The next clause provides the specific bit representation (e.g., Size starts on byte 0 from bit indexed 1 to 4.
- Finally, R is provided with its address in memory.
Implementation (in SPARK/Ada or C)
The Ada and SPARK languages provide most of the capabilities of modern imperative languages. The most notable property of how these capabilities are implemented is that they provide little room for compiler interpretation and avoid shortcuts. For example, there’s no implicit conversion, and doing something like pointer arithmetic easily requires five lines of code. However, the additional time spent during the actual coding phases is easily regained by the ease of verification, whether for code reading, testing, or static analysis.
At this point of the discussion it’s worth calling out an elephant in the room: using a new language may be a great idea for newly developed code, but more often than not there is a pre-existing environment that can’t be ignored. This is typically code from other projects or off-the-shelf libraries. This code was probably created in the C language, or maybe C++. This alone often drives the choice of a development language.
Fortunately, SPARK and Ada have been designed to integrate well with C environments. A few directives can map C directly to Ada and vice versa without the overhead of any wrapper code. This mapping can even be generated automatically.
Therefore, it’s perfectly reasonable – if not recommended – to start developing only a few components in SPARK or Ada while otherwise remaining in a C environment.
The main compiler technology available today for Ada and SPARK is GCC, though other can be made available. This means that SPARK and C code can be compiled using the same technology, with the same optimizations and code generation passes. As a result, there’s virtually no difference in performance between C and the SPARK code, and no penalty of having control flow from one language to the other.
Speaking to one of our earlier examples, let’s assume that a container is being used that was implemented in C. The C code that we’re trying to interface with looks like:

Outside of a declaration of an implementation coming from C, the specification is exactly the same in Ada/SPARK.

The Ada or SPARK code can use this procedure just as if it was implemented in Ada. Similar to import, export allows C to invoke a subprogram written in Ada. If needed, these interface layers can be automatically generated through binding generators.
Although compiling SPARK and C together addresses a number of use cases, there are still situations in which the final code must be C. Indeed, some users, while interested in developing in SPARK, still need to deliver C code to their customers.
A special compiler is available to cover this use case, the “GNAT Common Code Generator.” It essentially compiles a subset of the Ada language to C. With this technology, SPARK almost becomes a modeling language with outputs that are integrated in a C environment. It could alternatively be viewed as a way to deliver formally verified C code, with verification being performed at the SPARK level.
In the data representation example (the register case), using this piece of data in the code is very straightforward. Assigning a value would look like:
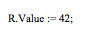
No bitwise operation is necessary here, as the compiler will generate the appropriate code automatically under the hood.
Verification
Ada and SPARK provide a lot of information in source code that can be used by all kinds of checkers. As the first line of defense, the compiler will detect a number of inconsistencies and can automatically insert dynamic verification in the executable during test phases, for example. With that level of information it’s possible to go beyond classical static analysis and apply program-proving techniques to demonstrate properties across the application.
With regard to lower level data structures, automatic consistency verification will also be performed. The compiler verifies that a specific size is enough to implement required data ranges, that there’s no data overlap, etc. In addition, formal proofs can be used to verify that the assigned values are always in range for any assignment.
Continuing another earlier example, assume that Push is called in a piece of code that we want to verify. For example, we could have the following statements reading numbers from an input file until it hits 0:
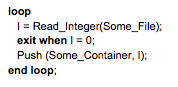
This Push call will be flagged as incorrect by SPARK tools because there’s no way to know that the loop will not hit the maximum capacity of container C. The prover can’t prove the precondition of Push, which should clearly be implemented at the level of the call, not within the called procedure. Another potential bug in the example code could arise if the end of the file is reached without hitting a 0. If proper preconditions are specified, the prover will be able to tell that there’s a check missing in the loop to verify that an input still needs to be read.
This kind of problem typically occurs at some point. If unit testing with coverage of corner cases is extensive enough, issues will be fixed at that level. They could, however, find their way into integration testing when real data starts to be fed into the system, or beta testing when users try to break the system. In the worst case scenario, some of these bugs find their way through deployment and need to be tracked down after being reported by a customer. The question is not whether they will be found, but rather how expensive fixing them is going to be when they are. The later they’re found, more people are involved in the chain and more investigation is required to identify the source, fix the issue(s), justify the fix, test the fix, re-deliver the product, etc. Using a technology that integrates verification early on – in this case, at the desk of the coder – goes a long way towards reducing the number of errors that slip through processes, and ultimately reduces the total cost of developing and maintaining robust software.
What’s old is new again
The Ada and SPARK approach is unique in the way it integrates software specification, implementation, and verification, providing a cost-effective method of producing software at integrity levels required by modern systems. Industries such as medical, automotive, and the Industrial Internet of Things (IIoT) have been on the lookout for an alternative to traditional C development, and Ada and SPARK provide a proven solution.
As a provider of the Ada language, AdaCore has observed a renewed interest in the technology over the past few years. Today’s constraints provide a good opportunity to try new things – or old things that are making a comeback.
AdaCore
LinkedIn: www.linkedin.com/company/adacore



