
Network and x86 processors team up in embedded networking applications
October 01, 2010

A new architecture is required to enhance x86 for high-performance applications.
The x86 architecture is widely used today in many embedded applications. Engineers and product managers recognize that these devices provide their products with market-leading computing performance, frequent innovation with backward compatibility, low-risk continuity of supply, efficient power consumption, supporting development tools and software, and an array of price options.
The fastest-growing area taking advantage of these benefits is embedded networking and communications design. In this area, the x86 processor is ideally suited for 10/100 Mbps and 1 Gbps applications. However, a new architecture is required to enhance x86 for high-performance applications, as networks scale to 10G, 40G, and 100G.
Requirements stress x86 abilities
New designs have several critical requirements that stress the capabilities of the x86 architecture:
- Higher performance: The one requirement that never changes is the need for more performance. The appetite for network bandwidth is insatiable with more users and more devices online, more bandwidth-hungry applications such as video, and new networks for mobile and cloud computing applications. With no end in sight, networks have moved beyond 10/100/1000 Ethernet to Nx1G and 10G, with 40G and 100G on the horizon. The performance requirement is not only limited to increasing raw bandwidth, but also must provide very low latency to handle real-time applications. Finally, sophisticated traffic management is being introduced to provide queuing, scheduling, shaping, and policing of traffic among thousands of types of applications.
- Security processing: Network security was once a rarity, and designs accounted for it with specialized security processors on an out-of-band or look-aside exception path. In modern designs, line-rate security processing and acceleration for computationally intense bulk cryptography functions are expected to be provided in-line on potentially every packet.
- Deep packet inspection: Deep packet inspection and L4-L7 packet processing were also historically treated as exceptions, being handled by separate external processors and regular expression engines. Many use cases in modern designs require the ability to make security and network processing decisions on information contained within the packets, far beyond primitive L2-L3 header information.
- Programmability: The list of applications and threats that can be found on networks is increasing daily. Product designs for network infrastructure and security devices must be highly programmable to adapt to new requirements without great cost or time constraints.
- Power efficiency: To meet new green computing requirements, increasing bandwidth and computation per packet cannot drive a linear or exponential increase in power. New designs must reverse the growth rates in power consumption, driving new levels of instructions per watt.
- Stateful processing: Virtually all of the requirements around deep packet inspection, load balancing, and security processing require a stateful, flow-based view of the entire communication session. Simple packet processing is no longer good enough, with the current OpenFlow specification defining a 10-tuple matching criteria.
The combination of these new requirements yields the need for much more bandwidth with significantly more processing per packet. Any one of these items can be a challenge for a general-purpose processor, and the combination of these new requirements puts significant stress on x86 in embedded communications designs that move beyond a few gigabits of performance.
The x86 hard cache wall
The x86 processor is ideally suited for the general-purpose computing requirements of many networking and security applications. Unfortunately, it also becomes a bottleneck in high-performance designs. The x86, as well as other cache-based architectures such as MIPS, cannot handle the simultaneous actions of high packet rate I/O, security processing, and deep packet inspection.
At 10G, 40G, and 100G, this combination of actions defines a very high touch rate and instructions for each packet over an increasing number of stateful series of packets that define a flow. In these scenarios, the gap between memory transaction rate and network throughput is pronounced. Standard methods to hide memory latencies such as multilayer caches become ineffective.
If one conservatively assumes that only 500 bytes (0.5 KB) of memory is required to maintain state information on a flow, that means 0.5 GB is needed to preserve the usefulness of the cache. This is several orders of magnitude more than the 12 MB of cache offered in the current top-of-the-line x86 CPUs.
Recently published test results shown in Figure 1 clearly illustrate the limitations of today’s leading x86-based CPUs.
|
|

The results indicate that as the number of stateful flows increases, the general-purpose CPU’s performance decreases substantially.
A new architecture
Recent advances in flow processing technologies allow designers to take advantage of the many benefits provided by x86 and scale them for use in 10G, 40G, and 100G designs. A new architecture shown in Figure 2 offers multiple workload-specific processors that maximize the performance of each critical design task. It features specialized networking-optimized coprocessors that augment x86 by removing the inefficient and burdensome workloads for which it is ill-suited. The design maintains the benefits and familiarity of x86 for all application and control plane processing. At the same time, it provides a powerful array of specialized multicore RISC processors optimized for network and security workloads.
|
|
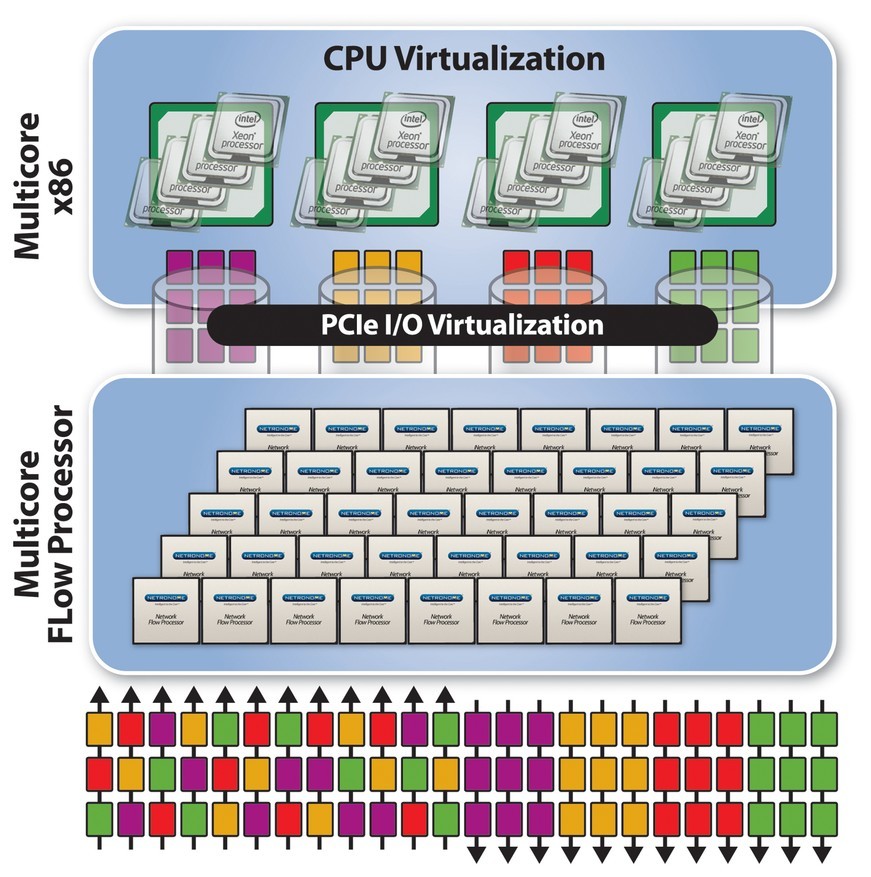
These flow processors handle lower-layer packet processing and accelerate higher-layer flow and application-level processing. This accelerated architecture utilizes the network-optimized cores for switching and routing, packet classification, filtering, stateful flow analysis, deep packet inspection, and dynamic flow-based load balancing. Additional network processing functions such as TCP termination and SSL offload can also be performed, further offloading the general-purpose CPUs. Traffic can be cleanly structured for transmission from the flow processors to the general-purpose cores for application processing, thereby increasing host performance. Finally, all communications between the data plane flow processors and the application and control plane processors can be orchestrated over a virtualized, high-speed PCI Express interface that takes further advantage of virtualization options with multicore x86 processors.
Applications for heterogeneous multicore designs
Many network and security products are ideally suited for this heterogeneous multicore design, which provides best-in-class x86 processing and new stateful flow processing. The notion of flows and active state can be found in firewalls, session border controllers, intrusion prevention systems, load balancers, and many other networking and security devices.
|
|

Netronome Systems 724-778-3290 [email protected] www.netronome.com




