Achronix Speedcore Gen4 eFPGA IP Fits AI/ML and Networking Hardware Acceleration
January 02, 2019
Press Release

The Speedcore Gen4 architecture adds the Machine Learning Processor (MLP) to the library of available blocks and delivers higher system performance for AI/ML applications.
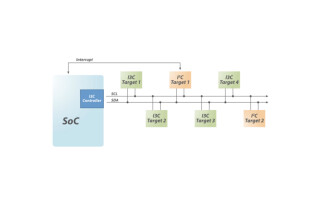
Achronix Semiconductor, a developer of FPGA-based hardware accelerators, recently announced the availability of its Speedcore Gen4 embedded FPGA (eFPGA) IP. The modular IP is aimed at compute, networking and storage systems for interface protocol bridging/switching, algorithmic acceleration, and packet processing applications. When integrated into users’ SoCs, Achronix claims that performance increases by 60 percent, power can go down as much as 50 percent, and die area can be reduced by 65 percent.
The Speedcore Gen4 architecture adds the Machine Learning Processor (MLP) to the library of available blocks and delivers higher system performance for artificial intelligence and machine learning (AI/ML) applications. MLP blocks are highly flexible, compute engines tightly coupled with embedded memories to give the highest performance per watt and lowest cost solution for AI/ML applications. The MLP exploits the specific attributes of AI/ML processing and increases performance through architectural enhancements that increase the number of operations per clock cycle.
As a complete AI/ML compute engine, each MLP includes a local cyclical register file that leverages temporal locality for optimal reuse of stored weights or data. The MLPs are tightly coupled with neighboring MLP blocks and larger embedded memory blocks. They support multiple precision fixed- and floating-point formats including Bfloat16, 16-bit, half-precision floating point, 24-bit floating point, and block floating point (BFP).
Achronix’s design tools include pre-configured, Speedcore Gen4 eFPGA example instances so developers can evaluate their results for performance, resource usage, and compile times.