
Enhancing AI Inference through Sparsity Support and Transformer Optimization for Minimizing Latency
September 16, 2021
Blog

AI models have become more complicated in recent times due to the escalating demand for real-time AI applications in various industries. This necessitates the deployment of high-performing, cutting-edge inference systems in an optimal way. TensorRT's latest version addresses these issues by bringing in additional capabilities to provide more enhanced and responsive conversational AI applications to their customers.
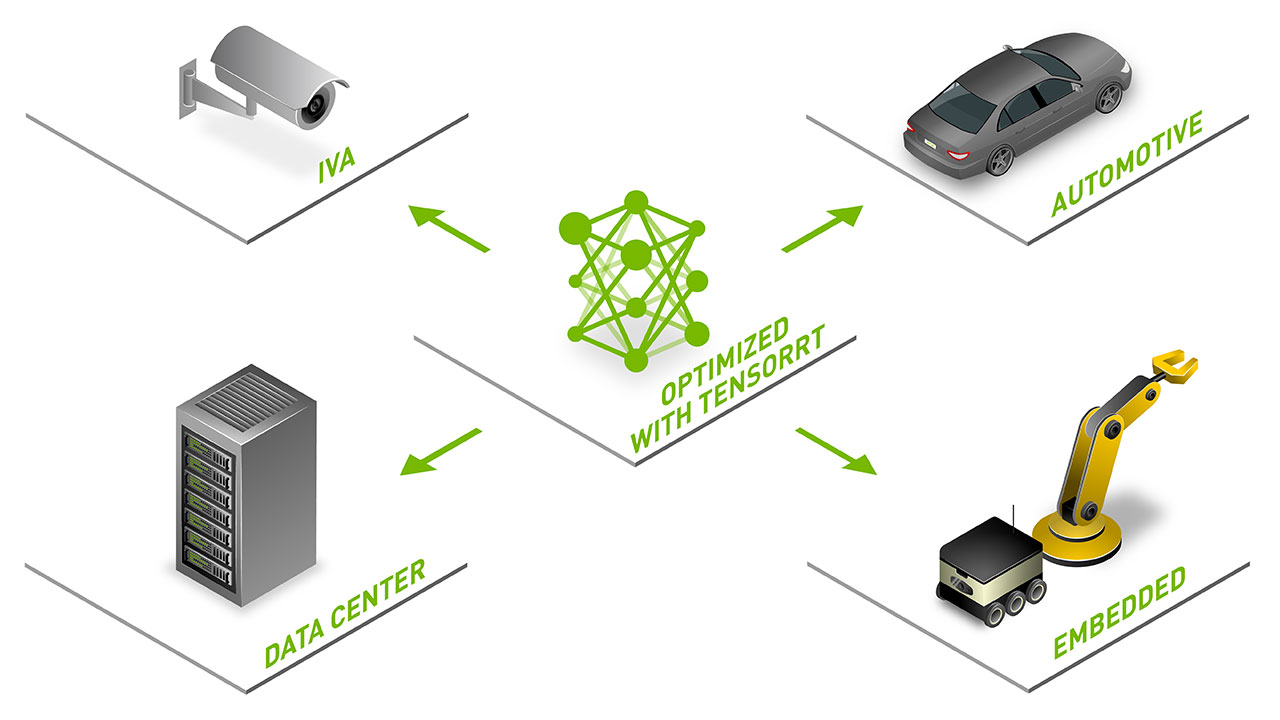
Image Credits: NVIDIA TensorRT
Overview of NVIDIA TensorRT 8
NVIDIA TensorRT is a high-performance inference platform that is essential for leveraging the power of NVIDIA Tensor Core GPUs. TensorRT 8 is a software development kit with enhancements designed to improve performance and accuracy for the increasing amount of AI inference occurring at the edge and in embedded devices. It allows extensive computational inference of TensorFlow and PyTorch neural networks.
When compared to CPU-only platforms, TensorRT delivers up to 40X higher throughput while minimizing latency. It allows you to start with any framework and rapidly optimize, validate, and deploy trained neural networks in production.
The new version incorporates sparsity on NVIDIA Ampere GPUs, which prunes weak connections that do not contribute to the network's overall calculation. Additionally, TensorRT 8 supports transformer optimization and BERT-Large. Transformer optimizations boost performance, while quantization-aware training improves accuracy.
What’s new in NVIDIA’s TensorRT 8?
The purpose of inference is to retain as much accuracy as possible from the training phase. The trained model can be run on hardware devices to get the customers’ lowest response time and maximum throughput. However, the necessity of being as precise as possible might sometimes clash with the amount of memory and throughput available at the edge. A well-trained, highly accurate model may be too slow to run.
So, TensorRT Version 8 incorporates the most recent advancements in the application of deep learning inference or trained neural network models to comprehend how data influences responses. It uses two main features to reduce language query inference time by half:
Sparsity with NVIDIA’s Ampere Architecture
Deep neural networks excel at various tasks, such as computer vision, speech recognition, and natural language processing. As the computational power required to process these neural networks increases, efficient modeling and computation become increasingly important.
Sparse is a new performance approach for GPUs with the NVIDIA Ampere architecture that boosts developer efficiency by decreasing computational processes. Other aspects of a deep learning model are less significant than others, and some can even be zero. As a result, there is no requirement for the neural network to do computations on specific weights or parameters. Therefore, NVIDIA can enhance performance, throughput, and latency by reducing nearly half the weight of a model using sparsity.
Reducing Inference Calculations by Transformer Optimization
In TensorRT 8, performance enhancements are achieved through transformer optimization. Quantization developers can utilize the trained model to perform inference with 8-bit computations (INT8). This decreases inference calculations and storage in the Tensor core substantially. INT8 is increasingly being used to optimize machine learning frameworks such as TensorFlow and NVIDIA's TensorRT to reduce memory and computing needs. Hence, NVIDIA can deliver very high performance on the Tensor RT 8 while maintaining accuracy.
For example, the Quantization Aware Training (QAT) has the potential to double accuracy. Thus, TensorRT 8 can double the performance of many models compared to its older version, TensorRT 7.
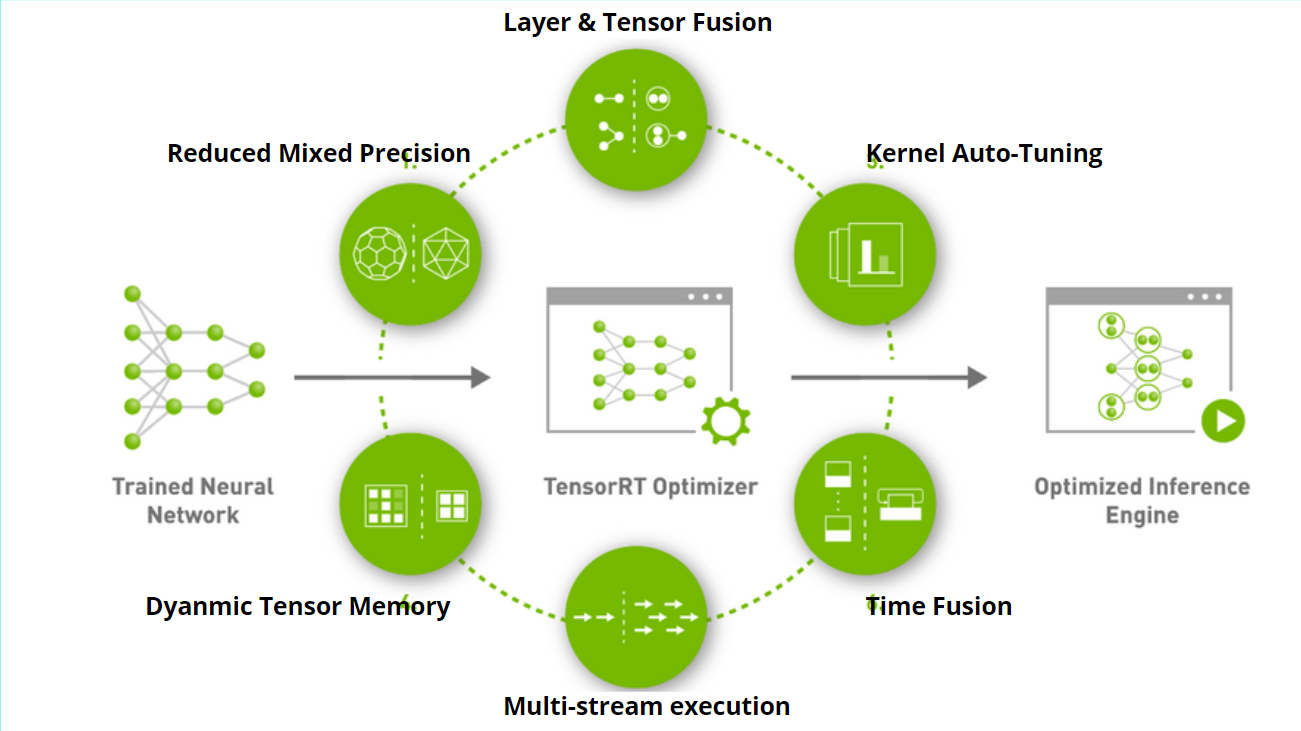
Image Credits: NVIDIA TensorRT
TensorRT is Deployed Across Numerous Industries
TensorRT’s better performance and accuracy make it a popular choice for industries such as Healthcare, Automotive, Internet/Telecom services, Financial services, and retail. For example, Tensor RT is used to power GE Healthcare's cardiovascular ultrasound systems. The digital diagnostics solutions provider used this technology to accelerate automated cardiac view detection on its Vivid E95 scanner. Cardiologists can make a more accurate diagnosis and detect diseases in their early stages by using an improved view detection algorithm. Furthermore, TensorRT is also used by Verizon, Ford, the United States Postal Service, American Express, and other well-known companies.
Along with the release of Tensor RT 8, NVIDIA also unveiled a breakthrough in Google’s BERT-large inference using Tensor RT. Bidirectional Encoder Representations from Transformers (BERT) is a transformer-based machine-learning technique for pre-training natural-language processing. A BERT-Large model takes only 1.2 milliseconds to analyze, allowing for real-time responses to natural-language queries. It means that companies can double or triple the size of their models for greater accuracy.
Language models like BERT-Large are used behind the scenes by many inference services. On the other hand, Language-based apps generally do not recognize nuance or emotion, resulting in an overall bad experience. Now, companies can deploy an entire workflow in milliseconds with TensorRT 8. These breakthroughs could pave the way for a new generation of conversational AI apps that provide users with a more intelligent and low latency experience.
You can head over to the official page of NVIDIA’s TensorRT for detailed information.

Saumitra Jagdale is a Backend Developer, Freelance Technical Author, Global AI Ambassador (SwissCognitive), Open-source Contributor in Python projects, Leader of Tensorflow Community India, and Passionate AI/ML Enthusiast.




{kind=link}
{kind=link}