
Notes on IoT Database Management - Part 1
April 30, 2019
Blog

IoT devices span all aspects of modern life ? industrial, automotive, medical, and commercial applications that affect us all.
The Internet of Things is not just a buzzword any more. Although the concept of intelligent connected devices has been discussed for decades, recently it has taken shape as an ecosystem of hardware devices, software, analytic platforms and standards connecting together industries, businesses and consumers.
IoT devices span all aspects of modern life — industrial, automotive, medical, and commercial applications that affect us all. These real-life applications create data streams and volumes of content-derived data (e.g. aggregations or results of analytics) that require near real-time storage and processing. And while IoT devices have retained many of the same properties as old-fashioned “embedded” devices, there are quite a few differences that IoT engineers and database management system vendors must address.
Data Volume and Connection Points
The high volume of data generated by devices has always been a concern for embedded database vendors, network infrastructure vendors and physical storage vendors. New data sources have emerged that generate orders of more data. The speed at which data are collected from various streaming sources, sensors, or generated by algorithms to then pass through IoT edge devices and gateways only compounds the demands on a system. Modern transponders’ frequencies are higher than before, sensors have greater precision, location services on mobile devices are routinely used by consumers for everyday chores, etc. Yet by their nature, edge devices don’t have enough resources — memory, persistent storage and CPU power - to analyze the data on their own, at least not while fulfilling the devices’ main purpose. Brakes must be able to stop a car, not analyze braking patterns to improve the overall efficiency of the brakes.
In the same vein, the number of connected edge devices is often much higher than it used to be. Not that long ago, systems managed dozens of connected devices. These days, the number of intelligent data collection points ("intelligent connected devices”) can be in the thousands or higher. In addition, the number of IoT devices can change in real-time within a single setup — hundreds of new sensors can be bought online at once, instruments and control mechanisms get replaced overnight, gateways are added or removed, etc. These changes often happen while the IoT environment remains operational.
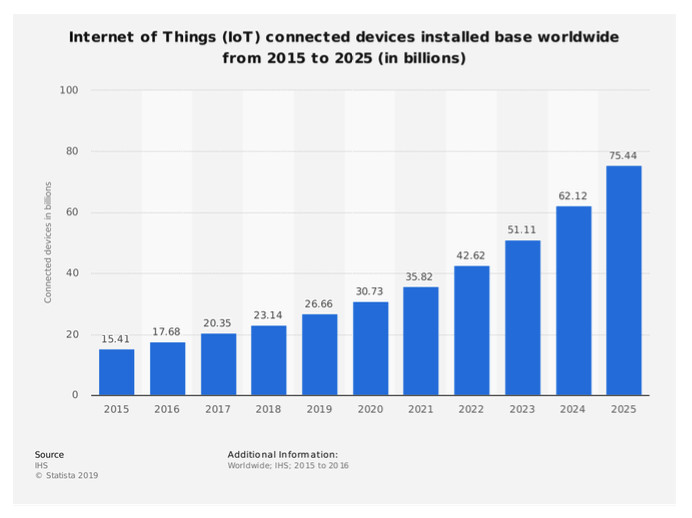
In general, the total installed base of Internet of Things (IoT) connected devices is projected to amount to 75.44 billion worldwide by 2025, a fivefold increase in 10 years (see chart).
The high volume of data, large and growing number of data collection and processing points, elastic real-time connectivity and functional scalability of the IoT environment impose new requirements on IoT database management:
- The database must be seamlessly integrated with communication facilities.
- There must be a well-balanced choice of database management features available at the edge; resource consumption must remain low, yet still allow for sufficient analytics to reduce the data flow to and from the cloud or server.
- The need for advanced scalable data management topology, including a number of layers, balancing data collection with aggregation and advanced processing.
Connectivity
One of the most distinctive properties of the IoT is their components’ openness to the world and the ability to utilize those devices for a multitude of different applications. Examples are everywhere, often woven into the fabric of society and often invisible to the naked eye. Building access control systems, smart dog collars, multi-purpose vending machines, location services, cashless payment systems, wireless outdoor weather sensors, the list goes on and on. These devices are truly “connected” and the processing of data routinely takes place outside the device itself.
Edge nodes' physical connectivity is often unpredictable. This is due to various media and bandwidth availability, the wide range of protocol stacks over which the devices are connected — Wi-Fi, Ethernet, cellular, as well as specialized stacks such as ZigBee, NFC and RFID, LPWAN, Low Energy Bluetooth, etc. Sometimes edge device connectivity is intermittent because of the physical device locations, or they’re battery operated and only phone home periodically to maximize battery life.
From the standpoint of data management, the database management system should be able to adjust its data replication patterns automatically based on various application-defined criteria. Specifically, fully integrated support for “push" and “pull" protocols and other astute replication algorithms are vital to preventing data loss and vulnerability.
Another small connectivity point worth mentioning is the fact that IoT devices are often connected to the outside world through the internet and their data collections ought to be accessible by web client applications written in Java, Python and/or script languages and through other web-related technologies. The common technique is for the database system to implement access to IoT device databases through web services via a lightweight REST protocol that provides end-point URLs to access the device’s data containers.
Summary
The ever-growing amount of data to be collected and managed on IoT edge devices poses challenges IoT engineers and database management systems vendors must continually research and address. It seems like the amount of data collected by the IoT, and the methods of collecting it, is growing almost as fast as the number of new systems. And while some variables remain constant such as the need for low resource consumption, the data processing demands only grow. Edge database management and analytics must be small and fast, yet powerful enough to enhance device functionality. Moreover, highly configurable database management becomes key. Some devices don’t have enough juice in them to run anything but a simple data collection task. Others are more capable. Intermittent and variable connectivity must be considered and planned for, while authorized accessibility should be seamless.
In part 2 of this series, I will discuss the nuances of other mandatory considerations including system adaptability, security and code quality.
McObject co-founder Andrei Gorine leads the company’s product engineering. As CTO, he has driven the growth of the eXtremeDB real-time embedded database system, from the product’s conception to its current wide usage in virtually all embedded systems market segments. Mr. Gorine’s strong background includes senior positions with leading embedded systems and database software companies; his experience in providing embedded storage solutions in such fields as industrial control, industrial preventative maintenance, satellite and cable television, and telecommunications equipment is highly recognized in the industry. Mr. Gorine has published articles and spoken at many conferences on topics including real-time database systems, high availability, and memory management. Over the course of his career he has participated in both academic and industry research projects in the area of real-time database systems. Mr. Gorine holds a Master’s degree in Computer Science from the Moscow Institute of Electronic Machinery and is a member of IEEE and ACM.




