
ARM redefines microarchitecture, IP for AI era
June 02, 2017
Blog

Like everything else in technology to date, smarter systems based on artificial intelligence (AI) require smarter processors. Several approaches to pr...
Like everything else in technology to date, smarter systems based on artificial intelligence (AI) require smarter processors.
Several approaches to processing machine learning inferencing algorithms (the act of making decisions based on learned patterns that will be performed largely at the network edge) have been adopted thus far, including the use of CPUs, GPUs, ASICs, DSPs, and FPGAs, each with their plusses and minuses. For instance, Karl Freund, a deep learning and HPC analyst for Moor Insights & Strategy recently wrote in Forbes:
“The data complexity and velocity determines how much processing is needed, while the environment typically determines the latency demands and the power budget.
“CPUs, like Intel’s Xeon and Xeon Phi in the datacenter and the Qualcomm Snapdragon in mobile devices, do a great job for relatively simple data like text and jpeg images once the neural network is trained, but they may struggle to handle high-velocity and resolution data coming from devices like 4K video cameras or radar… However, in many cases, the job may require a GPU, an ASIC like Intel’s expected Nervana Engine, or perhaps an FPGA programmed to meet the demands of a low-latency and low-power environment such as a vehicle or an autonomous drone or missile.”
Of course it’s not as cut and dry as simply using one in lieu of another. Again, Freund:
“Some applications, such as vision-guided autonomous systems, require a hybrid hardware approach to meet the latency and data processing requirements of the application environment. While the accelerators mentioned above do a great job of running the AI inference engine, sensor fusion, data pre-processing, and post-scoring policy execution requires a lot of special I/O and fast traditional logic best suited for CPUs.”
So, use a CPU for limited text and image processing, unless you need more. Then use a GPU. But for single-thread tasks you’ll still want a CPU. Unless you want low latency and reprogrammability, in which case you opt for an FPGA and hire a seasoned Verilog or VHDL programmer. How much does a custom ASIC run these days?
“DynamIQ” microarchitecture adds flexibility for AI embedded systems
Earlier this year, ARM made a significant revision to the multicore microarchitecture for its Cortex-A-class applications processors, introducing DynamIQ technology that the company claims will provide a 50x boost in AI performance on CPU cores over the next 3-5 years.
In addition to extending the big.LITTLE architecture from four cores to a possible eight, the DynamIQ microarchitecture redefines the cluster schemes for single-cluster homogeneous (up to four CPUs), dual-cluster heterogeneous (up to eight CPUs), and other dynamic cluster designs (Figure 1). For example, dual-cluster heterogeneous DynamIQ big.LITTLE architectures can leverage combinations of big (b) and LITTLE (L) cores ranging from four big and four little (4b+4L) to one big and seven little (1b+7L), allowing system on chip (SoC) designs to be optimized for power management, performance, etc. Along with dedicated AI processor instructions, DynamIQ technology provides significantly higher single-thread compute performance, as, for instance, a 1b+7L DynamIQ processor doubles the output of an octa-core LITTLE SoC.

[Figure 1 | ARM’s DynamIQ microarchitecture technology extends big.LITTLE implementations to eight possible CPU cores, enabling scalable multicore designs that can be tuned for a system’s AI requirements.] Slide 12
A redesigned memory subsystem in the DynamIQ microarchitecture provides a private L2 cache for each core and L3 cache that is shared by all cores, which increases efficiency, enables faster task migration, and improves power management (finer grained control over CPU speeds, faster state transitions). DynamIQ cores retain backwards compatibility despite the redesign, enabling existing binaries to be ported directly to new DynamIQ cores.
The right cores for the right kind of intelligence
In light of the DynamIQ architecture, ARM released two new Cortex-A-class processor cores this week that leverage the technology: The ARM Cortex-A75 (a replacement for the Cortex-A73 and -A72) and ARM Cortex-A55 (replaces the Cortex-A53).
The Cortex-A75 is a versatile “big” application core that represents a 50 percent single-threaded performance increase over current-generation processors at the same efficiency, yielding faster responsiveness for autonomous systems in the mobile, network infrastructure, and automotive markets. The Cortex-A55, on the other hand, is being positioned as the -A75’s DynamIQ “LITTLE” counterpart, improving efficiency by 2.5x over similar offerings for applications such as Internet of Things (IoT) edge gateways, consumer devices, and safety-certified industrial control and robotics systems.
However, perhaps the biggest advantage of DynamIQ technology when used with these cores is improvements to the AMBA interconnect that provide as much as 10x faster access to hardware accelerators and GPUs capable of doing heavy lifting in AI and machine learning applications (Figure 2). ARM also announced one such machine learning-optimized GPU this week, the Mali-G72 GPU core, which offers a 1.4x performance increase when computing machine-learning algorithms, 25 percent better energy efficiency, and 20 percent better area efficiency than its predecessor. As seen in Figure 3, the Mali-G72 exhibits 17 percent energy efficiency gains when computing core GEneral Matrix to Matrix Multiplication (GEMM) inferencing algorithms.

[Figure 2 | ARM’s DynamIQ microarchitecture technology provides up to 10x faster access to GPUs and hardware accelerators through the AMBA interface.]
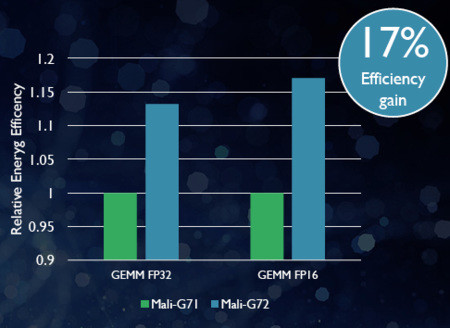
[Figure 3 | The Mail-G72 has been optimized for machine learning tasks.]
For designers of SoCs, the DynamIQ microarchitecture and new CPU and GPU cores join a host of other ARM technologies for efficiently and securely extending AI capabilities throughout a system, including the CryptoCell-712 security block and CoreLink GIC-600 interrupt controller (Figure 4).

[Figure 4 | The ARM Cortex-A75, Cortex-A55, and Mali-G72 GPU are core building blocks of a machine learning SoC design.]
Scaling AI for smarter systems
Until recently, many of the systems that would benefit most from AI and machine learning technology were unable to do so because the design complexity, power consumption, and cost constraints of available processing solutions. The DynamIQ microarchitecture and its corresponding technologies look to rectify that through scalability that can meet the requirements of almost any multicore system.
DynamIQ SoCs are expected to be commercially available in early 2018.
References:
[1] Strategy, Moor Insights and. “A Machine Learning Landscape: Where AMD, Intel, NVIDIA, Qualcomm And Xilinx AI Engines Live.” Forbes. March 03, 2017. Accessed June 02, 2017. https://www.forbes.com/sites/moorinsights/2017/03/03/a-machine-learning-landscape-where-amd-intel-nvidia-qualcomm-and-xilinx-ai-engines-live/#e834237742f8.



