
Neural Network Graphs Need Graph Streaming Processors
February 06, 2020
News
As technologies go, neural network processing is still in its infancy. There are still high-level questions to be answered. For instance, ?How do you actually execute a neural network graph?"
As technologies go, neural network processing is still in its infancy. As such, there are still high-level questions that need to be answered. For instance, “How do you actually execute a neural network graph?”
There are several possible approaches, but the emergence of neural networks – which are all graphs – has revealed some flaws in traditional processor architectures that were not designed to execute them. For instance, CPUs and DSPs execute workloads sequentially, which means that AI and machine learning workloads must be repeatedly written to non-cacheable, intermediate DRAM.
This serial approach to processing, where one task (or one portion of a task) must complete before the next one can begin impacts latency, power consumption, and so on. And not in a good way. Figure 1 shows how a graph workload is executed on these conventional processors.
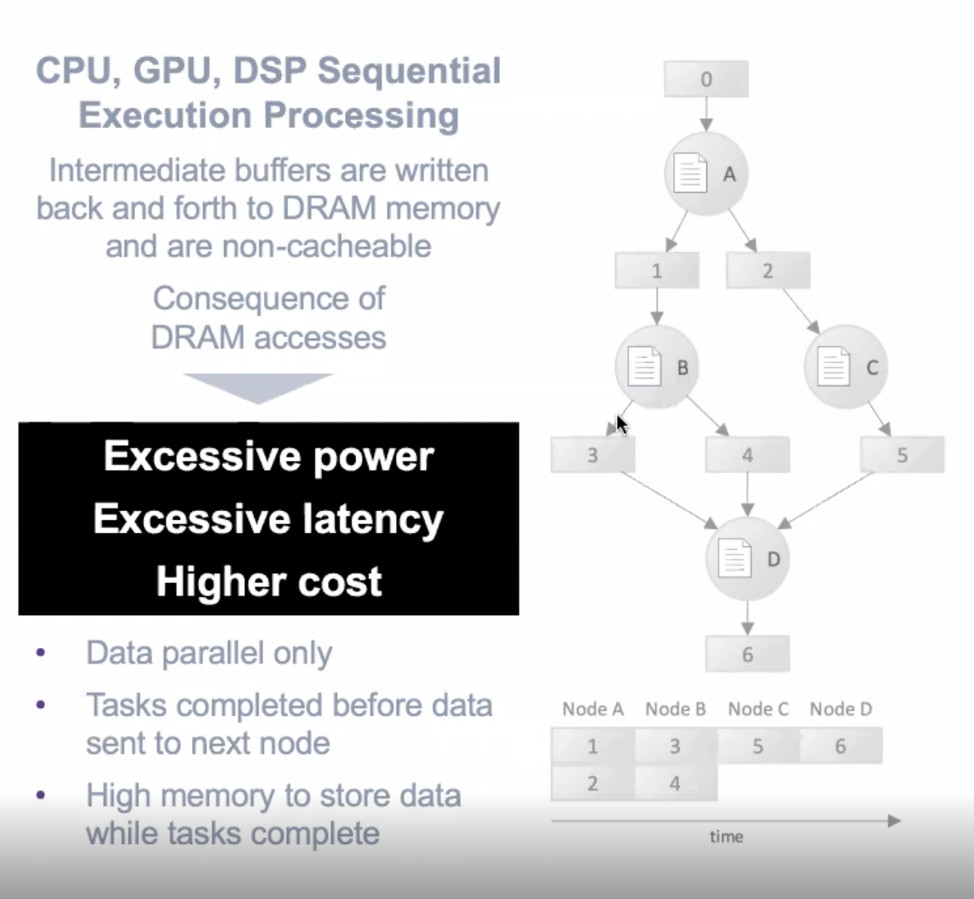
Figure 1. Serial execution of neural network graphs results in high power consumption, latency, and overall system cost.
In the figure, bubble nodes A, B, C, and D represent work functions, while the rectangles show the intermediate results generated by each node. Richard Terrill, VP of Strategic Business Development at Blaize (formerly ThinCi), explains the repercussions of processing neural network graphs in this way.
“Those intermediate results are typically quite massive and to store them on-chip can be very expensive,” Terrel explained. “You either make a really big chip. Or, more often, you send it off chip, wait for it to be completed. Once it's done, then you can load up the next node and run it.
“But what happens is the results have to be brought back onto the chip after B is loaded and run, then two is back brought back on after C is loaded and run. There's a lot of off-chip, on-chip, off-chip, on-chip transactions that are happening here.”
Geared Towards Graphs
As the use and application of neural networking technology grows, the state of the art must change. Blaize is developing a Graph Streaming Processor (GSP) architecture that it believes can scale with the AI and machine learning workloads of the future.
The company’s “fully programmable” chips contain an array of instruction-programmable processors, specialized data caches, and a proprietary hardware scheduler that bring task-level parallelism to neural network graphs. The architecture, shown in Figure 2, helps reduce external memory accesses, while the integrated GSPs and dedicated math processors run at only hundreds of megahertz to conserve power.

While Blaize is still keeping specifics of its GSP architecture close to the vest, from a high level the technology appears to address many of today’s graph processing challenges.
“The machinery, the underlying core technology, it's designed to implement and run data flow graphs with high efficiency,” Terrill said. “That's an abstraction, but it characterizes a lot of very interesting problems today that require you to be able to do different types of operations on it, different computation, arithmetic and control, arithmetic with different precisions, arithmetic with different operators, with dedicated math functions, and the like.
“Inside, if we peel it open, our proprietary SoC has an array of proprietary processors. They are CPUs of a class at one level, but they are programmed by our compiler with binaries to run inside of them,” he added.
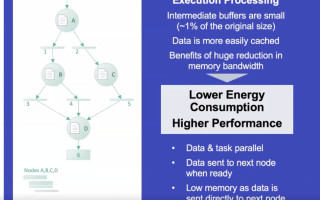
Figure 3 shows how the graph streaming process is efficiently executed with this machinery. As shown in the figure, the rectangles labeled 0, 1, 2, 3, 4, 5, and 6 represent the task parallels. Data is sent from the first parallel to the bubble node labeled “A”. From the bubble, it passes through a severely truncated intermediate buffer that allows tasks to continue executing without having to go off chip.
In theory, this means lower energy consumption, higher performance, and a massive reduction in required memory bandwidth. All of that can translate into lower system costs.

The purpose-built hardware scheduler that pairs with Blaize’s GSP technology allows developers to leverage this performance without having to understand low level details of the target architecture, which Terrill points out as key given that no human being could actually handle task scheduling in these types of workloads. The scheduler is so efficient, in fact, that it can reprogram cores based on context switches in a single clock cycle.
The scheduler is able to achieve this by running a map of the flow graph in parallel to the actual workload execution
“It can make decisions on single cycles of incoming data and intermediate results of what runs when and where,” Terrill said. “Not only is it programmable, it's single-cycle reprogrammable and there’s a big difference. You can’t do this type of work with something that’s fixed or if using a program counter to keep track of the work being done. It's extremely difficult to reprogram an FPGA. It takes half a second and you lose all your states. It can never keep up with this sort of speed at which people want things completed.”
The company’s test chip was developed on 28 nm process technology. Interestingly, however, Blaize plans to productize this technology through a series of industry-standard modules, boards, and systems.
The Software Side of GSP
A graph-native processor architecture of course needs graph-native software development tools. Here, the Blaize “Picasso” development platform allows users to iterate and change neural nets efficiently; quantize, prune, and compress them; and even create custom network layers if need be (Figure 4).
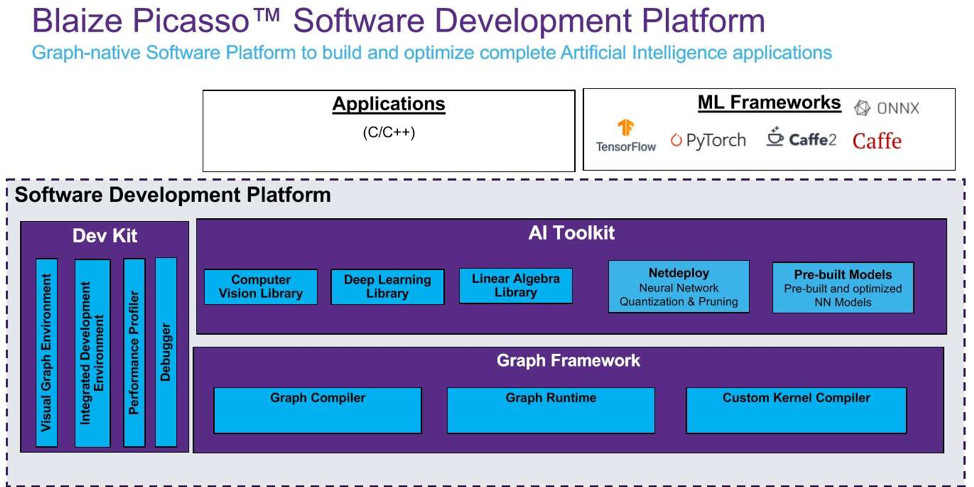
With support for ML frameworks like ONNX, TensorFlow, PyTorch, and Caffe, Picaso is based on OpenVX and employs a C++-like language that simplifies integrating the neural network portions of an application to other components in a software stack. Figure 4 shows the primary elements of Picaso – an AI Toolkit that assists with developing pre- and post-processing instructions and a Graph Framework that handles compilation.
Interestingly, after generating executables the compiler retains data flow graphs all the way through runtime, which allows the hardware scheduler to perform the aforementioned single-cycle context switches. It also automatically targets workloads to the most efficient cores on the chip to maximize performance and power savings.
But zooming in more closely on the above diagram, we come across “NetDeploy.” This is a technology that Blaize developed to automatically optimize existing models for deployment in edge devices.
it ends up being a really circular problem during the first pass of pruning and compression and pulling things out,” Terrill said. “The accuracy usually falls off the table and it goes back into the training phase to say, "Okay, well train it like this and do this and see what happens."
“It's not a very deterministic process. It takes a lot of cycles.”
Similar to tools like OpenVINO, NetDeploy allows users to specify a desired level of precision and accuracy and preserves those characteristics when optimizing the models into algorithms that will run at the edge. According to Terrill, a customer who was training on GPUs and deploying on FPGAs used NetDeploy to shrink model porting time from multiple weeks to a matter of minutes, all while retaining the accuracy and meeting memory footprint targets.
Graphing the Future
In the last 24 months we have seen many novel architectures emerge as AI workloads have become more prevalent and the ability to shrink silicon geometries has stalled.
Blaize provides a unique approach with its graph streaming processing (GSP) solution that spans compute, AI development and porting software, and, soon, even hardware that can be easily integrated into designs. This may allow the companies technology to be adopted more quickly than other emerging alternatives.
Blaize is focused on a range of applications, from automotive vision to facial recognition and beyond. To see the company’s technology in action at CES, watch the video below.

Perry Cohen, associate editor for Embedded Computing Design, is responsible for web content editing and creation, podcast production, and social media efforts. Perry has been published on both local and national news platforms including KTAR.com (Phoenix), ArizonaSports.com (Phoenix), AZFamily.com, Cronkite News, and MLB/MiLB among others. Perry received a BA in Journalism from the Walter Cronkite School of Journalism and Mass Communications at Arizona State university.



