
Tackling the Documentation Mountain: Using AI to Navigate User Guides
January 16, 2026
Blog

Documentation for semiconductor products and embedded systems software solutions is extensive, often reaching into thousands of pages. Navigating the mountain of documentation is time-consuming and potentially error-prone. This translates into high support costs for the companies selling these products and frustration for engineers.
Recently launched LLM-based AI solutions can address this problem, making it faster and easier for engineers to navigate complex documentation to find the information they need. Vendors using these solutions can reduce support costs by as much as 90%.
Generic AI solutions are not well-suited for this use case. In many cases, company policies don’t allow the use of generic AI solutions. But even if they are allowed, they are not built for technical analysis, and they cannot be trained on private data without risk of leaking confidential information. Furthermore, they are not designed to generate long deliverables like test cases or certification documents.
Solving this problem requires an AI solution that is customized for this use case, trained on an Enterprise’s documentation, and that provides enterprise-grade security to ensure confidential information is not leaked to public LLMs.

The Documentation Mountain
The complexity of microprocessors, microcontrollers, SoCs, connectivity ICs, and sensor chips continues to grow. For engineers integrating these chips into an end product, understanding the details of how these chips work is a significant challenge. Engineers integrating these solutions into a product are faced with a mountain of documentation.
This problem is not limited to hardware products. Embedded software solutions such as operating systems, communication stacks, and security libraries are also quite complex. They come with extensive documentation provided describing the use and integration of these solutions.
Engineers can spend a significant amount of time searching through the various documents provided for a single product to understand how to best integrate these products. This challenge is exacerbated by the fact that, in some cases, not all documentation is consistent. Information found in a user’s guide may be superseded by information found in release notes or errata documents.
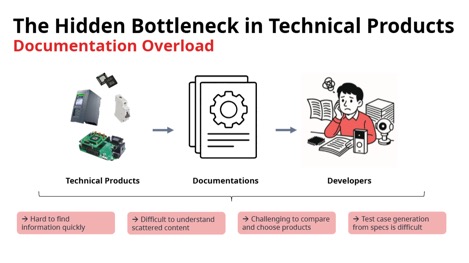
This can result in a number of problems, including:
- Time wasted searching for the right information
- Frustration when engineers implement a feature as described in a user guide, only to later find that the errata document shows that a different approach is required, resulting in rework and lost time
- Heavy support burden for the company providing the hardware or software solution
- In the worst case scenario, companies switch to a different vendor, resulting in lost revenue for the company providing the embedded solution
Taming the Documentation Mountain
Navigating and understanding complex and extensive user documentation is an ideal use case for LLM-based AI solutions. Modern AI solutions can be trained on a company’s technical documentation and be used to provide engineers using these products with a virtual Subject Matter Expert (SME).
In addition to training on user documentation, an enterprise-grade private LLM solution should provide integration with developers’ tools such as Jira, GitHub, Confluence, etc. This integration enables automated training of the LLM with data from these documentation and code bases stored in these solutions.
Use of such an SME allows engineers to quickly and easily pinpoint the information that they require to integrate products. This AI-based SME can be used by:
- Potential customers can quickly understand a product’s features and capabilities
- Engineers who are integrating the product to understand interfaces, APIs, and integration requirements
- QA teams to verify proper integration, define test cases, and edge scenarios
- Vendors' support team to reduce support costs and more quickly answer customers’ questions more quickly
The Need for a Private LLM
A company’s product documentation is confidential, and many vendors only release this information under a non-disclosure agreement (NDA). To ensure confidential information is not leaked, companies need a private LLM with enterprise-grade security.
Public LLMs, if not used carefully, will use data provided to them in queries to continue to train the model. As a result of these privacy concerns, many enterprises have banned or placed strict limitations on the use of public LLM tools such as ChatGPT. Public LLMs, if not used carefully, will use data provided to them in queries to continue to train the model.
Generic AI solutions also struggle with accuracy, especially across large, complex document sets. If Vendor A wants to use a public LLM to help developers navigate its documentation, it will have several issues to contend with.
- Public LLMs have already been trained with a massive set of information, which undoubtedly includes details on the vendor’s products under question. Some of this public information will undoubtedly be inaccurate.
- A public LLM may confuse information on Vendor A’s solutions with its competitors.
- Public LLMs are not designed to generate structured deliverables like certification documents or test cases.
A private LLM, such as the solution provided by Understand Tech, allows a company to train the LLM with its own data without risk of inadvertently leaking data to a public LLM. Ideally, the LLM will provide enterprise-grade security features, including the ability to control where data is hosted to ensure compliance with security regulations such as SOC2 and GDPR. Other important secure features include end-to-end encryption and integration with an enterprise's Single-Sign-On solutions.
Summary
As semiconductor products and embedded software solutions grow in complexity, engineers are finding it more challenging to integrate these solutions into their end products. This results in increased development costs, higher support costs for the vendors providing these products, and frustrated customers.
LLM-based AI solutions that are trained to understand vendors’ product documentation can dramatically reduce the time spent searching for information in the product documentation and reduce errors caused by inconsistencies in documentation. This helps engineers be more productive and reduce support costs for the vendors producing these products.
Naama BAK is an entrepreneur with 15 years of experience in tech. He is the founder of Understand Tech, a generative AI platform for enterprises, and Trustii.io, a machine learning platform for data science challenges. He previously held roles at NXP Semiconductors, Orange, and Safran, working in cybersecurity across research, development, product marketing, and business development. He holds a Computer Science Engineering degree and an MBA.

Naama BAK is an entrepreneur with 15 years of experience in tech. He is the founder of Understand Tech, a generative AI platform for enterprises, and Trustii.io, a machine learning platform for data science challenges. He previously held roles at NXP Semiconductors, Orange, and Safran, working in cybersecurity across research, development, product marketing, and business development. He holds a Computer Science Engineering degree and an MBA.



