Choosing the Right Silicon for Edge AI: How Intel, AMD, NVIDIA, and Arm Are Shaping the Next Generation of Distributed Computing
February 17, 2026
Blog
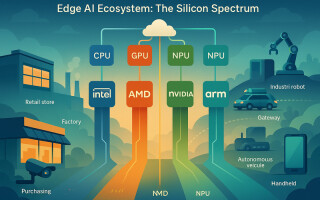
Edge computing devices, from retail cameras to factory controllers and logistics endpoints, are rapidly becoming frontline AI systems. The modern edge stack blends CPUs, GPUs, and increasingly NPUs (neural processing units) to deliver low‑latency, on‑device intelligence. This article compares how Intel, AMD, NVIDIA, and Arm pursue edge AI differently and offers CIOs a practical decision framework to align silicon, thermals, and software ecosystems with real workloads and operating constraints.
Introduction: Why Edge AI Is Reshaping Enterprise Compute
Enterprises are distributing AI closer to where data is created, i.e., stores, plants, vehicles, campuses, and field sites, to cut latency, preserve privacy, and keep operations resilient even when bandwidth is constrained. Modern NPUs offload inference from CPUs/GPUs, enabling faster local tasks (e.g., vision filters, speech, OCR) with better battery efficiency and thermal behavior, which are key to stable edge systems. For example, Microsoft’s AI Hub is curating NPU‑aware applications, signaling a broader software pivot toward on‑device acceleration on Windows PCs and other endpoints.
The Compute Engines at the Edge: CPU, GPU, and NPU
- CPU — The System Orchestrator: Coordinates OS, app logic, and data prep.
- GPU — The Parallel Workhorse: Drives high‑throughput math for video, imaging, and larger models.
- NPU — The Efficiency Engine: Handles inference with high performance‑per‑watt, improving responsiveness and thermal stability by offloading sustained AI tasks. Across silicon, NPUs now underpin OS features and third‑party apps designed to run locally.
For CIOs, the practical takeaway is simple: CPUs keep the device responsive, GPUs handle bursty, heavy AI, and NPUs sustain day‑to‑day inference efficiently, especially valuable in bandwidth‑limited or energy‑constrained environments.
The Vendor Strategies: What Each Is Really Optimizing For
1) Intel: Platform‑first for fleet manageability and balanced AI
How Intel thinks: Intel positions edge AI as a systems challenge. Its Core Ultra (Series 2) platforms combine CPU cores with integrated Arc GPU and an NPU in a power‑efficient package, with certain H‑series SKUs claiming up to 99 “total platform TOPS” for diverse inference workloads. The vPro portfolio emphasizes remote manageability, stability, and long‑term software support, which are relevant to large commercial fleets.
What it means for deployments: As more applications become NPU‑aware, sustained tasks (noise reduction, object detection, vision filters) migrate off CPU/GPU, improving battery and temperature behavior in distributed endpoints. Intel is also signaling further NPU efficiency gains in the upcoming Panther Lake (Core Ultra series 3) built on Intel 18A.
Best fit scenarios:
- Managed Windows fleets (inspection, logistics, campus safety) where vPro, remote provisioning, and ISV compatibility matter.
- Mixed workloads needing flexible scheduling across CPU/GPU/NPU without discrete accelerators.
2) AMD: Deterministic AI and functional safety paths for real‑time systems
How AMD thinks: AMD’s edge strategy spans Ryzen AI (with XDNA NPUs) for client/embedded PCs and Versal AI Edge Gen2 for deterministic pipelines from sensor input to inference to control logic, with documentation indicating functional safety features and timing predictability for regulated environments.
What it means for deployments: Ryzen Embedded 8000 integrates CPU, RDNA 3 GPU, and XDNA NPU, offering practical on‑device AI in 15–54W TDP envelopes; AMD cites up to 16 TOPS on the NPU and up to 39 platform TOPS, useful for moderate vision/robotics workloads without a discrete accelerator. For safety‑critical automation, Versal AI Edge Gen2 provides deterministic response and safety tooling suitable for ASIL/SIL‑governed use cases.
Best fit scenarios:
- Industrial robots and control systems require predictable timing and functional safety paths.
- Embedded PCs need moderate AI performance and stable thermal behavior.
3) NVIDIA: Software‑led perception with industrial‑grade edge modules
How NVIDIA thinks: NVIDIA leads with the developer ecosystem, such as JetPack, Isaac (robotics), and Metropolis (vision analytics), plus production‑ready Jetson modules for extended temperature, shock, and vibration profiles. Jetson AGX Orin Industrial advertises up to ~248 TOPS, ECC memory, and long‑life specifications, helping teams move from prototype to scaled deployments quickly.
What it means for deployments: Teams building multi‑camera perception, sensor fusion, and tracking benefit from NVIDIA’s reference pipelines and microservices, lowering integration time and risk.
Best fit scenarios:
- Vision‑heavy autonomy (rail inspection, agricultural robots, safety analytics) where perception dominates the compute mix.
- Organizations that value software/SDK maturity as much as silicon, to accelerate development timelines.
4) Arm: “AI everywhere” under ultra‑low‑power budgets
How Arm thinks: Arm enables partners to build tightly integrated CPU+NPU systems optimized for milliwatt‑level power. The Cortex‑A320 (Armv9) introduces sizable ML uplift vs. Cortex‑A35, and the Ethos‑U85 NPU adds efficient transformer operator support, with Arm framing the platform as capable of on‑device models approaching one billion parameters for IoT‑scale devices.
What it means for deployments: Handhelds, gateways, and distributed sensors can run meaningful AI workloads such as vision, speech, and sensor fusion without compromising battery life, thanks to close CPU/NPU coupling and efficient memory access.
Best fit scenarios:
- Ultra‑low‑power edge nodes where energy consumption and form factor outweigh raw TOPS.
- Distributed sensing systems and compact endpoints needing local AI with tight thermal margins.
The “Why” Behind the Specs: Patterns CIOs Should Recognize
- Heterogeneous computing is universal, but the purpose differs.
Intel emphasizes fleet manageability and balanced AI; AMD targets deterministic control and safety; NVIDIA optimizes developer velocity for perception workloads; Arm scales AI under tight power budgets. Your selection should follow the workload and operating context, not just TOPS. - NPUs are shifting from “checkbox” to “workhorse.”
Microsoft’s AI Hub now highlights NPU‑aware apps, and OS features increasingly rely on NPUs, enabling longer battery life and more consistent responsiveness as sustained inference moves off CPU/GPU. - Industrial variants are becoming mainstream for edge AI.
NVIDIA’s Jetson AGX Orin Industrial illustrates how platforms can scale TOPS while meeting reliability requirements (temperature, shock, vibration, ECC), unlocking advanced computer vision and sensor fusion at the edge. - Determinism and safety are rising requirements.
In regulated robotics/automation, Versal AI Edge Gen2 documents safety features and deterministic pipelines that align with ASIL/SIL expectations. - Hybrid edge–cloud is the default architecture.
Local inference delivers speed/privacy; the cloud handles model updates, fleet management, and federated learning. Microsoft’s recent platform updates for AI development across CPU/GPU/NPU reinforce this hybrid pattern in enterprise environments.
Who Wins Where: A Simple Mapping
- Real‑time perception with multi‑camera streams (robots, inspection, traffic analytics): Favor ecosystems with mature vision stacks e.g., NVIDIA Jetson + JetPack/Isaac/Metropolis, to accelerate dev and move predictably to production.
- Windows‑based field fleets (inspection, logistics, EHS): Intel Core Ultra platforms + vPro provide manageability, security posture, and NPU offloading for sustained tasks.
- Safety‑critical robotics/control loops: AMD Versal AI Edge Gen2 for deterministic pipelines and documented safety paths.
- Embedded PCs needing moderate AI without discrete accelerators: AMD Ryzen Embedded 8000 (CPU+GPU+XDNA NPU) in scalable TDPs.
- Ultra‑low‑power gateways/handhelds: Arm Cortex‑A320 + Ethos‑U85, where milliwatts matter more than raw TOPS.
Trends to Watch (12–36 Months)
- NPUs scale up, and scheduling gets smarter.
Intel’s Panther Lake preview points to higher NPU efficiency and programmability; expect smarter placement across NPU/GPU to keep thermals in check. - Industrial SKUs go mainstream.
More vendors will ship hardened modules akin to Jetson Industrial offerings to meet enterprise reliability demands without sacrificing AI throughput. - Windows and AI platforms double down on hybrid development.
New Windows AI Foundry capabilities target model optimization, fine‑tuning, and deployment across client and cloud, making “local + cloud” a baseline for edge AI fleets.
Executive Checklist: How to Choose
- Start with the workload, not the silicon.
Perception‑heavy? Safety‑critical? Windows fleet? Map scenarios to ecosystems that minimize integration time and operational risk. - Thermals and enclosure constraints dictate architecture.
Plan early for power/heat budgets. Use NPUs for sustained inference and reserve GPUs for burst workloads. This preserves responsiveness and device stability. - Lifecycle and manageability shape TCO.
Large fleets benefit from vPro manageability and long‑term support; regulated automation benefits from deterministic pipelines and documented safety paths. - Software portability reduces lock‑in.
Favor frameworks that span silicon via ONNX Runtime Execution Providers (e.g., TensorRT for NVIDIA, OpenVINO for Intel, QNN for Qualcomm). This keeps options open as hardware evolves. - Pilot against real duty cycles, not lab demos.
Validate sustained loads, thermal behavior, and latency with representative data streams. Tune NPU/GPU limits to match actual field conditions and uptime targets.
Bottom Line
Across all architectures, the CIO priority is clear: align compute, thermals, and software strategy to the workload—not the spec sheet. The right choice depends on whether you need manageability at scale, deterministic control, perception‑first tooling, or ultra‑low‑power intelligence. With NPUs becoming core to everyday inference and ecosystems maturing rapidly, the next 12–36 months will reward teams that design for portability and hybrid edge–cloud operations from day one.
Sources & Further Reading
- Intel Core Ultra (Series 2) overview & edge brief (up to 99 TOPS, vPro manageability): Intel Core Ultra Processors page, Edge Product Brief PDF, Intel Newsroom—Commercial vPro portfolio.
- Intel Panther Lake (series 3) on 18A: Architecture preview, By‑the‑numbers.
- AMD Ryzen Embedded 8000 (XDNA NPU), TOPS claims: Product brief, Product page.
- AMD XDNA architecture & Versal AI Edge Gen2 (determinism/safety): XDNA overview, Versal Gen2 TRM.
- NVIDIA Jetson AGX Orin Industrial (TOPS, ECC, extended specs) & ecosystem: Technical brief, NVIDIA Technical Blog.
- Arm Cortex‑A320 & Ethos‑U85 (IoT edge AI, transformer support): Cortex‑A320 overview, Ethos‑U85 TRM/overview, Armv9 edge AI platform news.
- Windows AI Hub & NPU‑aware apps: Windows Developer Blog, Computerworld coverage.
- ONNX Runtime Execution Providers: EP overview, TensorRT EP, OpenVINO EP, QNN EP.
- Hybrid dev across client & cloud (Windows AI Foundry): Windows Developer Blog (Build 2025).

Bhanu Handa is a Lead Product Manager at Dell Technologies, specializing in rugged computing solutions for industrial and defense environments. With a proven track record of planning, launching, and scaling rugged notebooks, tablets, accessories, and software, Bhanu focuses on enabling frontline teams through purpose-built technology. His work emphasizes improving operational uptime, reducing total cost of ownership, and advancing digital transformation in high-impact sectors.